[LG]《Reinforcement Learning with Rubric Anchors》Z Huang, Y Zhuang, G Lu, Z Qin... [Inclusion AI] (2025)
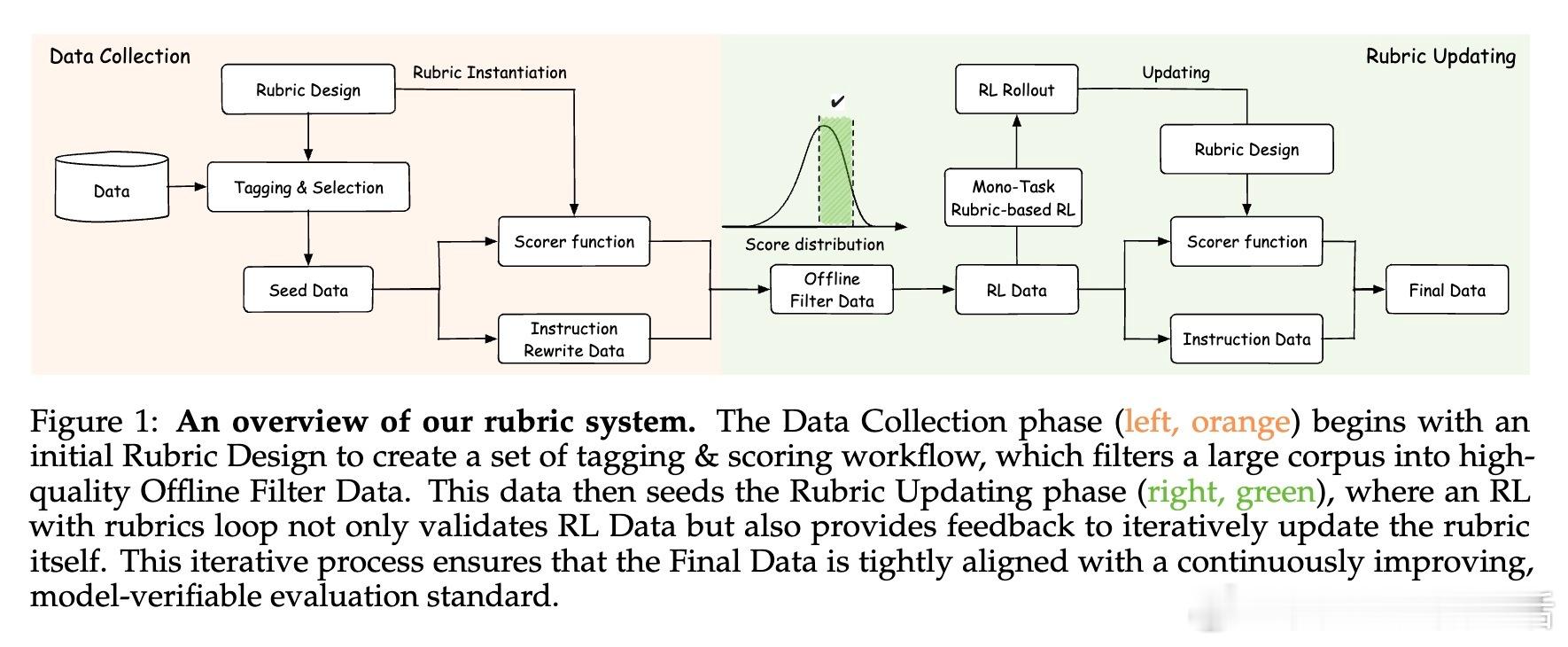
Rubric Anchors(Rubicon)为强化学习带来新突破,突破传统依赖可验证奖励的局限,实现对开放性、人文类任务的高效训练。核心亮点包括:
• 创新奖励机制:采用超过1万条多维度、结构化rubric作为评分锚点,支持自动化、多维度评价,涵盖主观和复杂输出,超越简单对错判定。
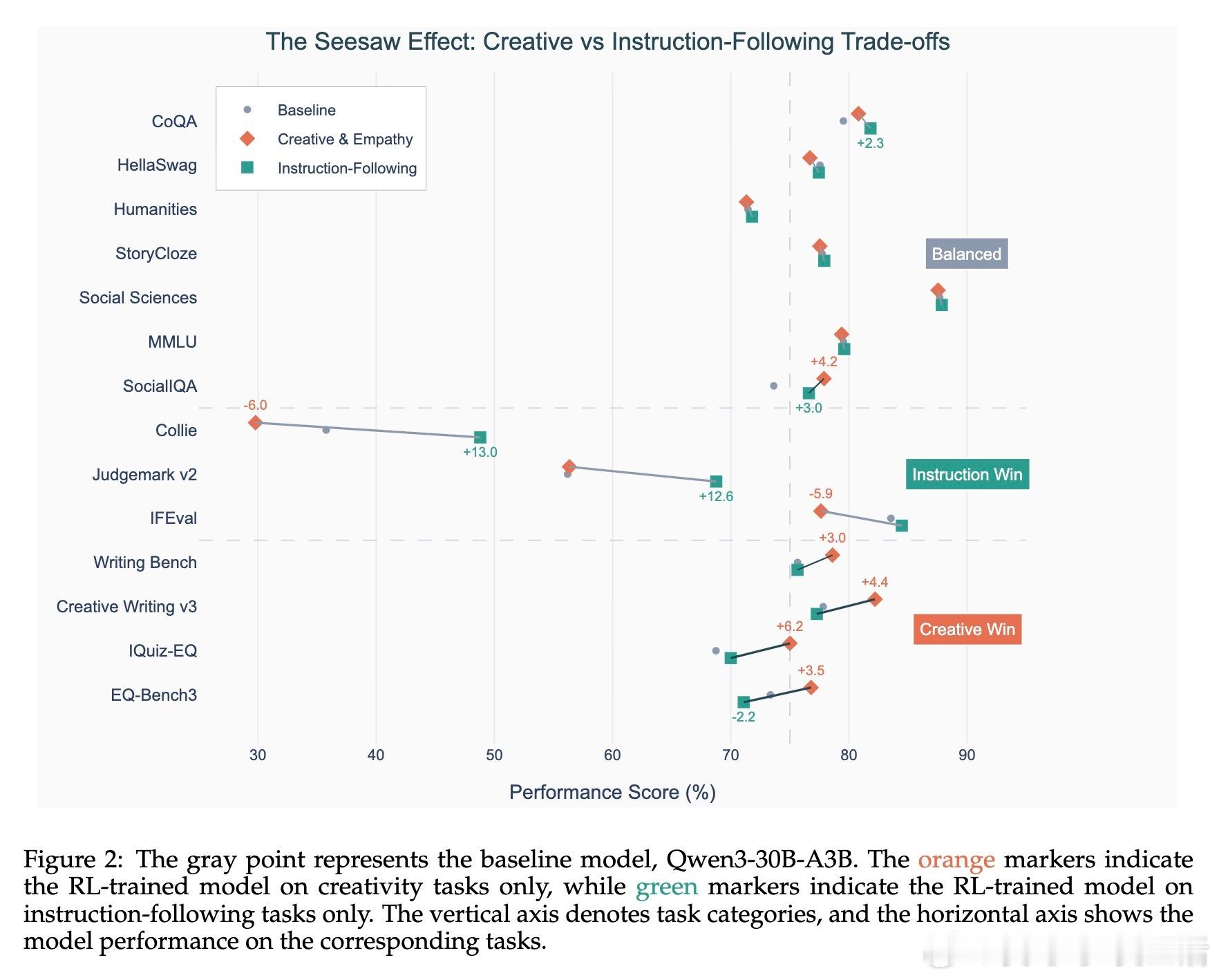
• 高效训练表现:仅用5K+训练样本,实现对人文创作、情感理解等开放式任务的5.2%绝对提升,超越671B规模DeepSeek-V3模型2.4个百分点,且保持数学推理等通用能力稳定。
• 风格可控输出:rubric作为显式锚点,有效抑制“AI感”与说教式语气,生成更具人类情感和风格多样性的文本。
• 多阶段RL策略:先强化指令遵循和约束处理,再扩展至创意与社交任务,解决多目标训练中“跷跷板效应”,兼顾创造力与规范性。
• 反作弊防御:针对奖励黑客行为设计专门rubric,提升训练稳定性和模型质量,防止投机取巧。
• 深层设计洞见:rubric的多样性、粒度与质量对模型表现至关重要,合理的数据筛选和训练流程是成功关键,揭示了开放式任务强化学习的新范式。
Rubicon为非验证型任务强化学习开辟了广阔前景,提出了可解释、细粒度、多维度的奖励设计新框架,推动LLM向更具人文关怀和创造力的方向迈进。
了解详情🔗 arxiv.org/abs/2508.12790
大模型强化学习评价体系人文AILLM优化开放式任务