OptimalThinkingBench:评估大型语言模型的“过度思考”与“思考不足”
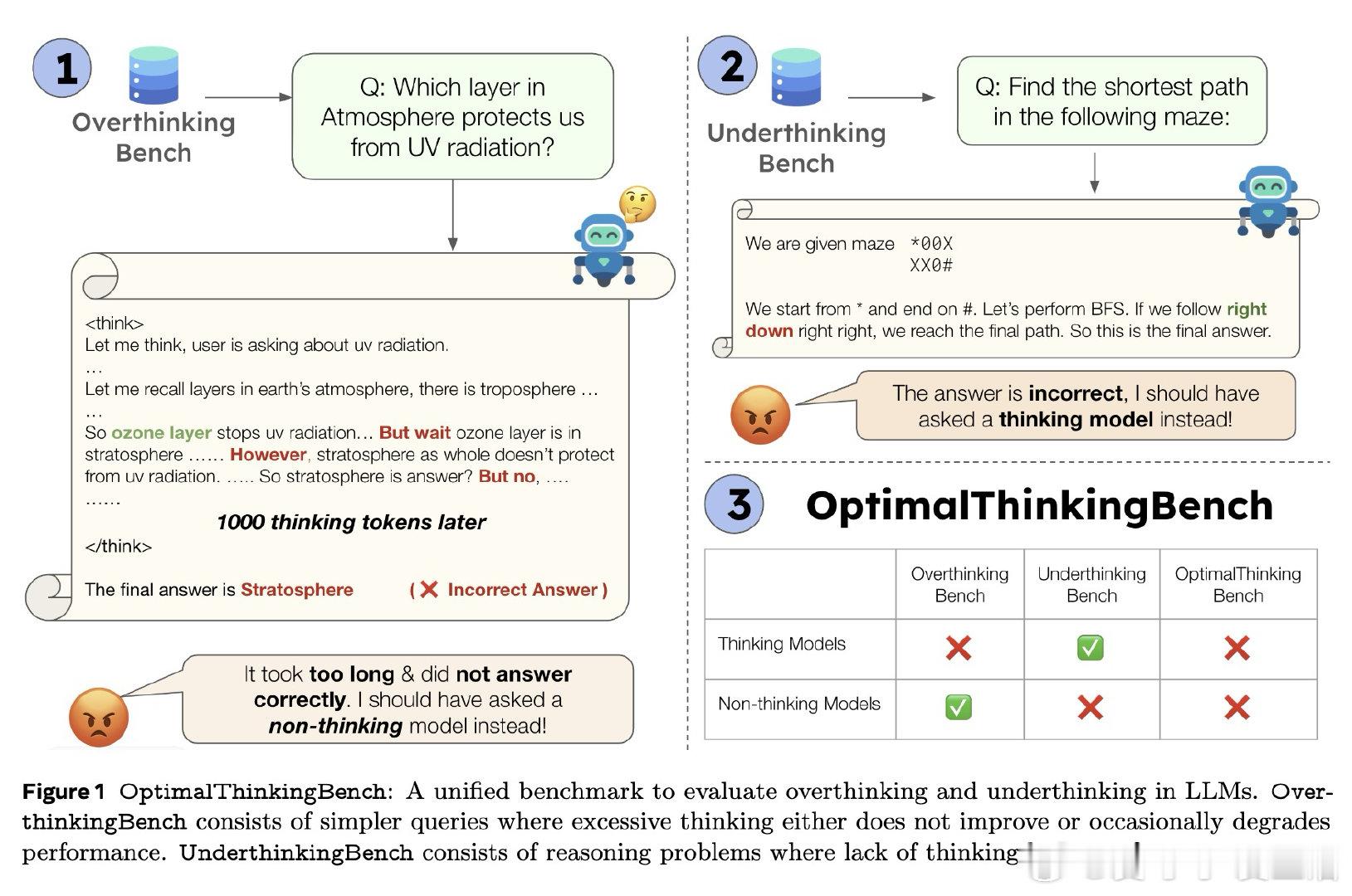
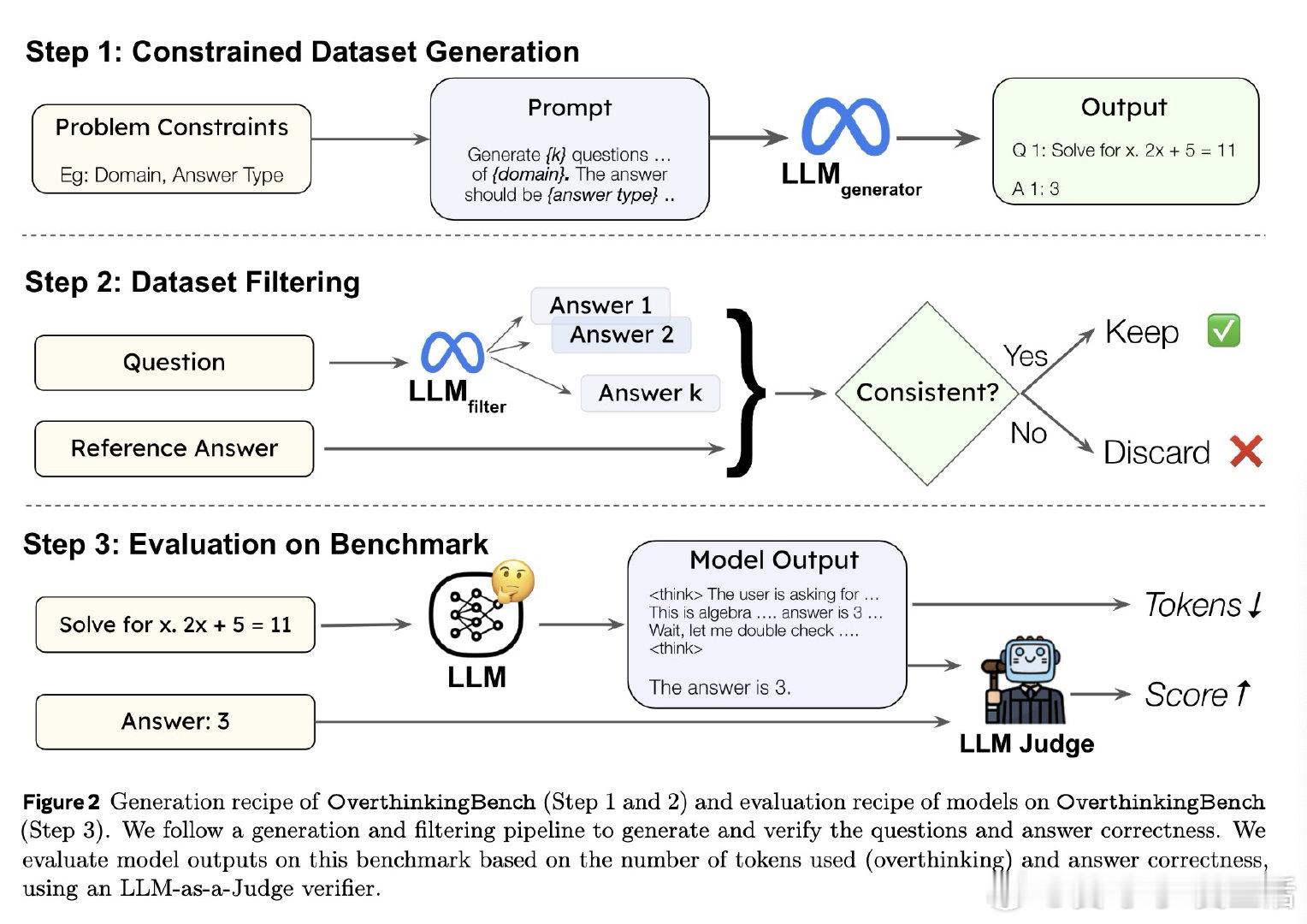
• 统一基准,涵盖72个领域的简单查询(OverthinkingBench)与11种复杂推理任务(UnderthinkingBench),全面检测模型在不同难度任务上的思考效率与准确性。
• 创新指标AUCOAA(过度思考调整准确率)与标准准确率结合,形成综合F1分数,量化模型在避免过度与不足思考间的平衡能力。
• 33款主流思考与非思考模型评测显示:
- 思考模型在简单查询上常产生数百个无效推理token,耗时高且无性能提升,用户体验与成本受损。
- 非思考模型虽快速高效,但在复杂推理上明显思考不足,准确率远低于较小的思考模型。
• 现有优化方法(惩罚过度思考、思考模式路由、提示优化)均未突破效率与表现的根本矛盾,提升有限。
• 发现:思考量与领域相关(理工科多于人文),且多选题选项数量线性增加过度思考,提示模型难以自适应调整计算资源。
OptimalThinkingBench提供动态生成与验证机制,防止基准污染,适应模型能力提升,推动未来统一高效的思考型LLM研发。
详见👉 arxiv.org/abs/2508.13141
大型语言模型 人工智能 自然语言处理 模型评测 计算效率