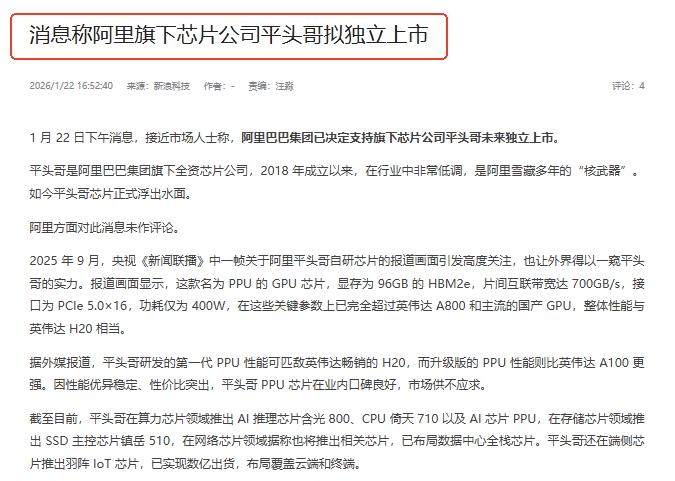
梁文锋又冲上热搜了! 这次既不是团队内讧也不是技术翻车,反倒给AI圈扔了颗惊雷。 没有发布会造势,没有官微预热,甚至连一句官方说明都没有,新模型就这么“藏”在代码里曝光了。 谁能想到,全球AI圈翘首以盼的技术大瓜,居然是靠扒GitHub代码挖出来的? 2026年1月21日,就在DeepSeek推理模型R1发布一周年的当天,有开发者意外发现,其官方更新的FlashMLA项目代码中,频繁出现一个从未公开的标识——“MODEL1”。 要知道,FlashMLA可不是普通代码库,而是DeepSeek独创的、专门适配英伟达高端GPU的核心加速工具,是其模型实现低成本、高性能的关键。 在涉及的114个核心文件里,MODEL1被明确提及31次,更离谱的是,它还多次与现有主力模型V3.2并列呈现。 懂行的人一眼就懂:这绝不是简单的版本优化,而是一套全新的架构体系,极有可能是DeepSeek传闻中2月要发布的下一代旗舰模型V4的技术雏形。 更吊人胃口的是,梁文锋团队连一丝风声都没露。 反观国内其他AI厂商,动辄开万人发布会,吹完“弯道超车”再放概念视频,最后产品迟迟落地不了。 而DeepSeek倒好,等外界扒出代码时,MODEL1的底层技术早已趋于成熟,甚至已完成多架构GPU适配——在最新的英伟达B200显卡上,128头配置的内核实现,居然只支持MODEL1,不支持V3.2。 这种“闷声憋大招”的操作,直接让全球AI圈炸了锅,也让梁文锋的热搜彻底爆了。 有人说这是饥饿营销,可代码不会说谎,技术沉淀更骗不了人。 回溯这一个月的动作就能发现,DeepSeek的布局早有铺垫。 2026年1月12日,梁文锋联合北京大学发表论文,提出“AI记忆模块(Engram)”,解决了传统模型知识检索低效的痛点。 紧接着,另一篇关于“优化残差连接(mHC)”的新训练方法论文上线,进一步夯实了模型性能基础。 业内专家拆解后确认,这两项前沿技术,恰好对应MODEL1在稀疏计算、缓存管理上的核心革新。 这意味着,MODEL1绝非临时拼凑的噱头,而是经过长期研发、已进入工程转化阶段的实锤产物。 梁文锋敢这么低调,底气全来自R1模型过去一年闯下的硬战绩。 2025年2月,R1模型横空出世,直接冲进全球AI推理模型榜单前列,硬生生把Meta、Stability AI等国外巨头拉下马。 更关键的是,DeepSeek选择将R1完全开源,不锁API、不藏核心技术,让全球开发者自由二次开发。 这步棋看似让利,实则精准戳中了西方垄断的命门——当时国外主流模型要么闭源收割溢价,要么半开源设技术壁垒。 R1的开源,不仅打破了“开源AI是国外天下”的迷信,更直接引发英伟达、微软等巨头股价波动,倒逼它们被动调整策略拥抱开源。 如今,R1已覆盖全球140个国家的开发者,印尼教育公司、俄罗斯Yandex等海外企业主动找上门合作,中国开源AI第一次形成了全球共创的生态。 周鸿祎在2026年AI预言中就明确提到,以DeepSeek为代表的中国开源模型,正成为全球AI根技术生态的核心力量。 而MODEL1的悄然现身,正是这场突围战的又一记重拳。 它不是简单的技术迭代,而是中国AI从“跟跑”到“制定规则”的信号——不再靠炒作博关注,而是用代码、用性能、用生态说话。 要知道,梁文锋的底气背后,还有幻方量化的坚实支撑,其2025年收益均值达56.55%,超700亿的管理规模,让DeepSeek能沉下心搞长期研发,不用被资本裹挟着追热点。 反观那些唱衰中国开源AI的声音,早已被事实狠狠打脸。 从过去被国外卡脖子、技术封锁,到如今主动输出开源方案,让国外巨头被迫跟风,我们靠的从不是口号,而是实打实的自主创新。 MODEL1的曝光,不是结束,而是中国AI打破西方垄断的新起点。 这场没有硝烟的战争,我们不靠炒作、不靠妥协,只用技术实力赢尊重,这样的崛起,才够体面、够彻底! 信源:DeepSeek梁文锋喊话罗永浩:靠嘴年入过亿,为啥非得做科技?-雷科技