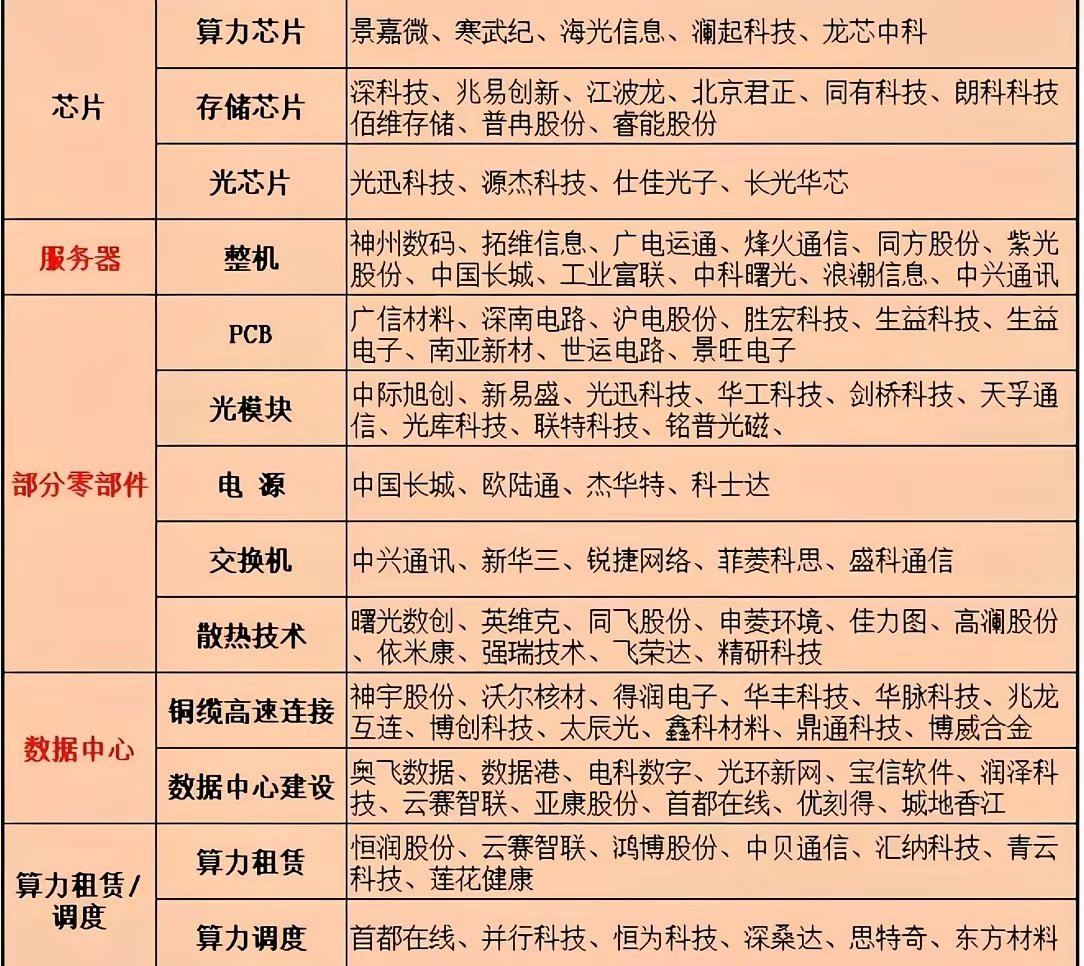
当人工智能和云计算推动数据中心算力两年翻一番时,连接芯片的“数据血管”却成了瓶颈。传统可插拔光模块像独立的“收发信站”,电信号传输距离远、功耗高,已经跟不上AI对高带宽、低延迟的需求。 于是,一场让光引擎“靠近”计算芯片的技术革命悄然展开,核心就是近封装光学(NPO)与共封装光学(CPO)。
NPO把光引擎从可插拔模块中解放出来,做成独立的光学小芯片,和GPU、ASIC等计算芯片并排装在同一载板上,通过≤150mm的短距PCB连接——就像把“外卖取餐口”搬到了“灶台”隔壁,既保留了光引擎的可插拔特性,又大幅缩短了信号传输距离。 这种设计的好处很直接:光引擎坏了只需单独更换,不用整板报废,维护成本低;而且光引擎和芯片分离散热,避免了GPU高温影响光器件性能,系统更稳定。 阿里已经把NPO用在超节点设计里,连接柜间的computer tree和switch tree,海外顶尖大厂也在准备实际应用。 而CPO更激进——直接把光引擎和计算芯片共封装在同一基底或插槽里,传输距离从厘米级降到毫米级,堪称光互联的“终极形态”。 它的优势是极致的性能:功耗比传统模块降50%以上,带宽密度提升5-10倍,延迟低至5-10ns,完美匹配AI超算的需求。 但代价也不小:光引擎和芯片紧密集成,坏了要整板更换,维护成本高;光电元件密集堆叠导致散热难度陡增,得用氮化铝基板加微通道液冷才能解决;而且良率低、成本高,当前价格是传统模块的8-10倍。
从技术演进看,NPO是CPO的“过渡跳板”。短期(2026-2027年)NPO会先爆发,全球市场规模从15亿美元增至45亿美元,渗透率30%-40%,国内华工科技、光迅科技的1.6T NPO出货量会大幅增长;中期(2028-2029年)随着封装工艺突破和成本下降,CPO会逐步规模化,台积电的COPA平台量产将把成本降到传统模块的2-3倍,谷歌等大厂会批量部署;长期(2030年后)CPO会成为3.2T/6.4T超高速光互联的标准方案,和NPO形成差异化竞争——NPO退守边缘计算、金融数据中心等更看重维护便捷性的场景,CPO则主导高端AI数据中心。
这场革命里,产业链的机会也在清晰浮现。光引擎是CPO/NPO的“心脏”,天孚通信作为英伟达核心供应商,市占率约30%;光芯片是核心,源杰科技的InP激光芯片、仕佳光子的AWG芯片已经打破海外垄断;高速PCB和封装基板需求暴涨,胜宏科技的CPO专用PCB价值量是传统的2-3倍,订单饱满;液冷散热成了CPO的刚需,英维克的液冷方案已经通过英伟达认证。 当光引擎离计算芯片越来越近,NPO和CPO不仅解决了当下的数据传输瓶颈,更在为未来3.2T、6.4T的超高速场景铺路。 对于数据中心来说,这不是选择题,而是必须跟上的技术浪潮——毕竟,AI的算力需求不会等,“数据血管”的进化,从来都是算力革命的先声。