昨天有网友在评论区问我啥时候聊聊 Grok 4,现在来交作业了。
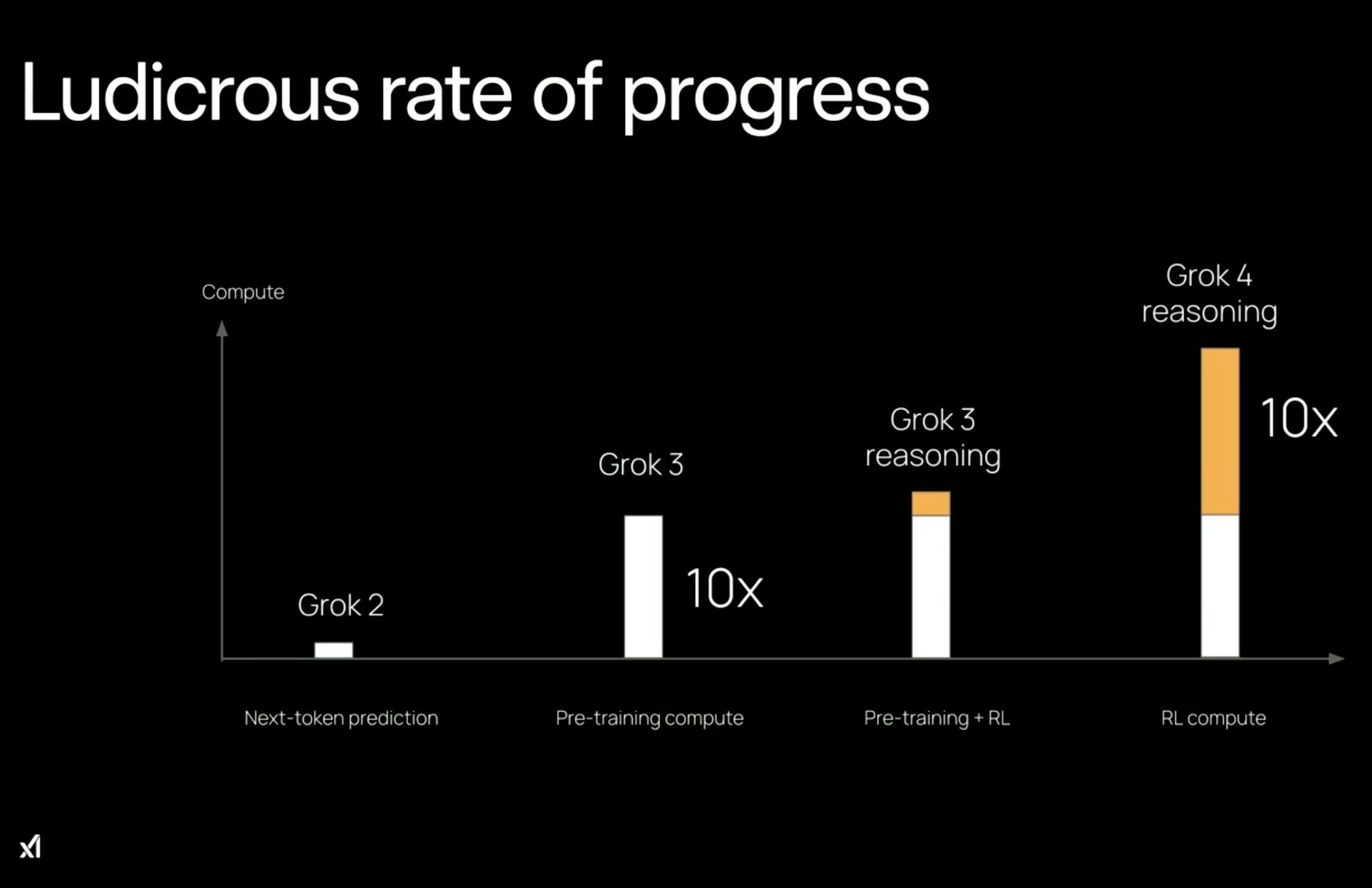
- Grok 3 的算力投入是 Grok 2 的 10 倍,而 Grok 4 的算力投入是 Grok 3 的 10 倍,两个数量级,Grok 2 到 4,算力加大了 100 倍。
但你看表,昨天 xAI 联创 Tony Wu 直播也说了,从 Grok 3 到 Grok 4,是强化学习(RL)的算力投入增加了 10 倍。
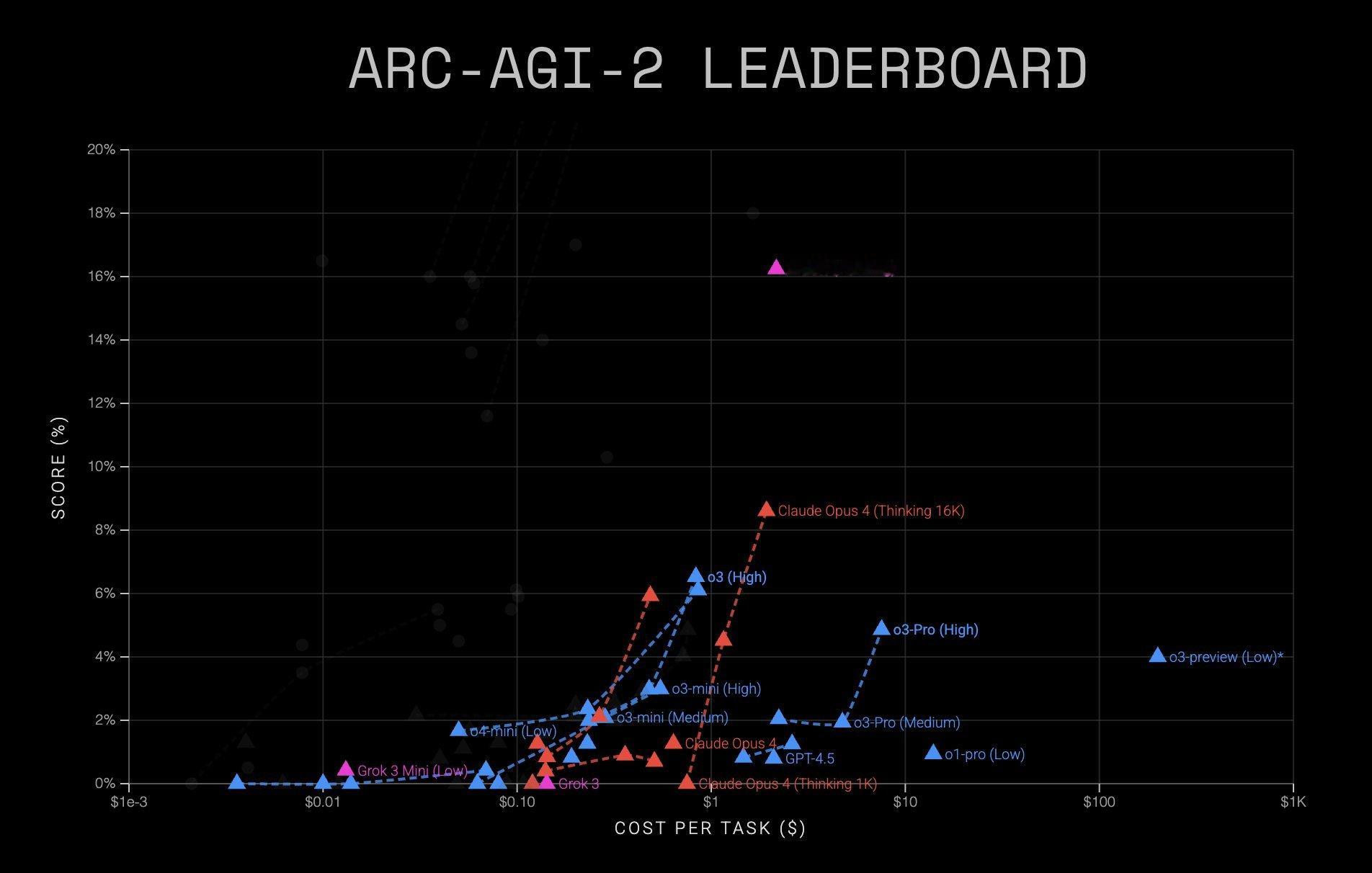
这个策略比当前任何其他模型在 RL 上投入的算力都更多,也给 Grok 4 带来了一系列非常好的性能上的体现。典型如 ARC-AGI-2 基准测试中,Grok 4 取得了 15.9% 的准确率,相比已有的最佳模型 Claude Opus 4 几乎翻倍。
在人文科学终极考试 HLE 测试中,Grok 4 Heavy 是 44.4%,比已有的最佳模型 Gemini 2.5 Pro 的 26.9% 同样是大幅增长。也就是 Elon Musk 所说的「在所有领域都达到了博士级别的水平,甚至比博士更强。」
这些都得益于 RL 带来的复杂推理能力的提升。
不过——
我记得 GPT-4.5 发布之后,xAI 联创 Igor Babuschkin 在某个帖子下评论,他怀疑有些公司(没有点名)之所以没能训练出比 Grok 3 更好的模型,是因为没能掌握所有的训练细节。对 xAI 来说,预训练的 scaling law 依然是有效的。
但从 Grok 3 到 Grok 4,xAI 在预训练的算力投入上几乎没有变化,对吧?
之所以提这个,是因为预训练决定基础模型,RL 决定新能力的涌现,二者缺一不可。为什么 Grok 4 的预训练算力投入没有变化,一种可能是当下的投入产出比,放在 RL 上收益更大。
- Grok 4 的推理能力通过使用工具进一步加强了,这里 xAI 的突破是「将模型对工具的使用融入到了训练环节」。Elon 补充说,今年晚些时候会赋予 Grok 4 使用有限元分析、计算流体动力学等特斯拉或 SpaceX 研发用到的工业级工具,这可能会进一步增强 Grok 4 的推理能力。这算一个有趣的细节。
- 发布会后面 xAI 提到未来的规划,一是兼顾速度和智能的编程模型,会在未来几周内发布。二是多模态能力,Elon 补充未来 xAI 会让模型在图像、视频和音频的理解能力上实现飞跃。将投入超过 10 万块 GB200 训练视频模型,未来 3 - 4 周内就将启动训练工作,最终,模型将实现 pixel in, pixel out。
这一点看,xAI 作为创业公司,在 AGI 的几个不同 bet 上是全面出击的。现在其实已经开始分化,比如 Anthropic 对多模态没有兴趣,几乎 all-in 编程。比如 OpenAI 通过 o 系列 RL 不断 scaling 是不是就能实现 AGI。
但 xAI 和 Google DeepMind 更接近,所有路线全都要,即使 Sora 已经半凉了,但 xAI 依然表达了对视频模型的浓厚兴趣。
- 总的来说,到 Grok 3,xAI 基本拿出了一个 SOTA 模型,但也没有领先,到 Grok 4,xAI 开始在许多 benchmark 上大幅领先。
关键是这两个模型的发布间隔不到 5 个月,包括 122 天搭了一个 10 万卡超算集群,我相信这个速度是 xAI 拿下累计超 250 亿美元融资,投资人持续加钱的关键因素。