Video-XL-2模型解析
Video-XL-2 技术解析与应用
模型架构
Video-XL-2 由视觉编码器(SigLIP-SO400M)、动态 Token 合成模块(DTS)和大语言模型(Qwen2.5-Instruct)组成。视觉编码器逐帧提取特征,DTS 融合时序信息并压缩数据,最终通过模态对齐输入 LLM 进行推理。
训练策略
采用四阶段渐进训练:前两阶段初始化 DTS 并完成跨模态对齐;第三阶段用高质量视频文本数据增强理解能力;第四阶段通过指令微调优化复杂任务响应。
效率优化
1. 分段预装填:将长视频分块处理,降低计算开销。
2. 双粒度 KV 解码:关键片段用稠密 KVs,次要片段用稀疏 KVs,提升解码速度。支持单卡处理万帧视频(如 A100)。
性能表现
在 MLVU、Video-MME 等基准上超越轻量级开源模型,接近 720 亿参数大模型水平。时序定位任务(如 Charades-STA)表现优异


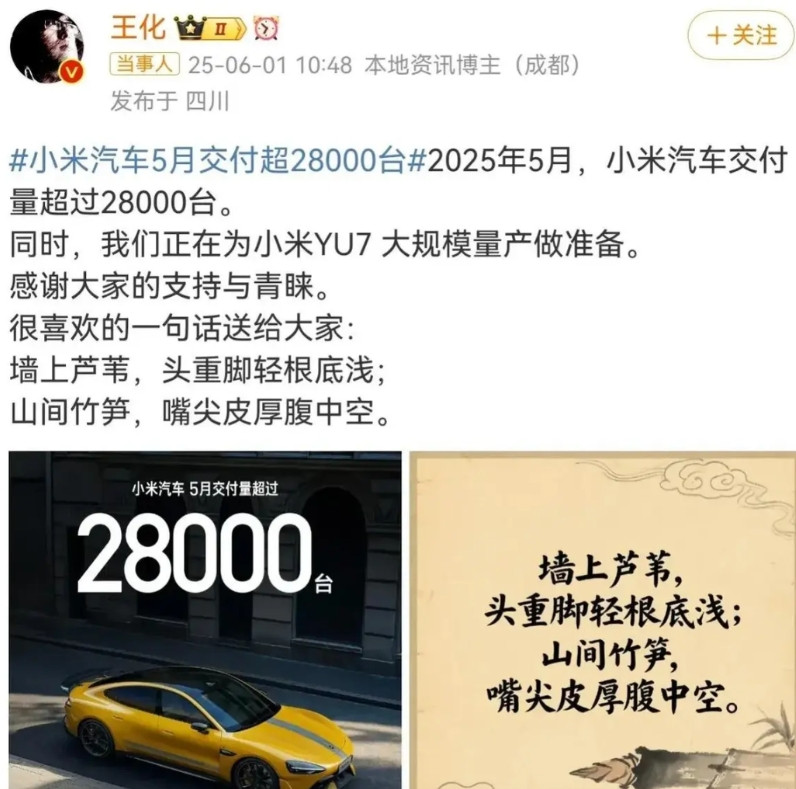
![雷总又出来拉预期了~[doge]我之前猜入门26.59万,中配28.99万,顶配](http://image.uczzd.cn/689554394205016576.jpg?id=0)


![澎湃OS这个指纹快捷功能用习惯了挺方便,如果能自定义就完美了[doge][doge][二](http://image.uczzd.cn/4036846019852938230.jpg?id=0)