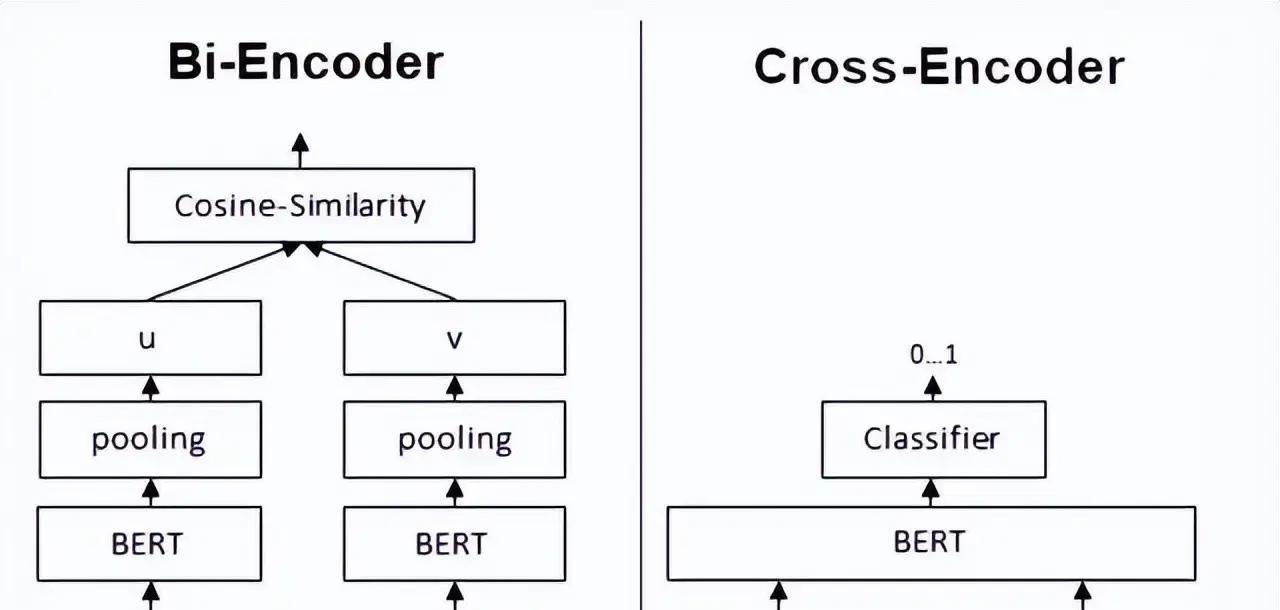
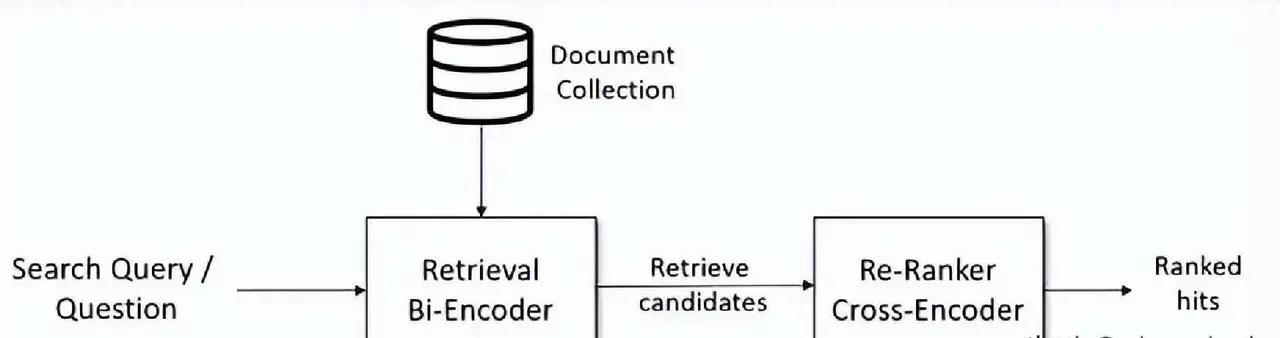
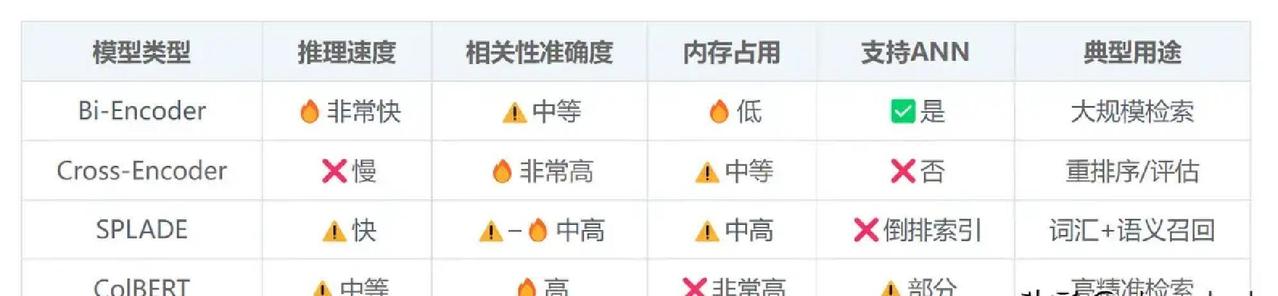
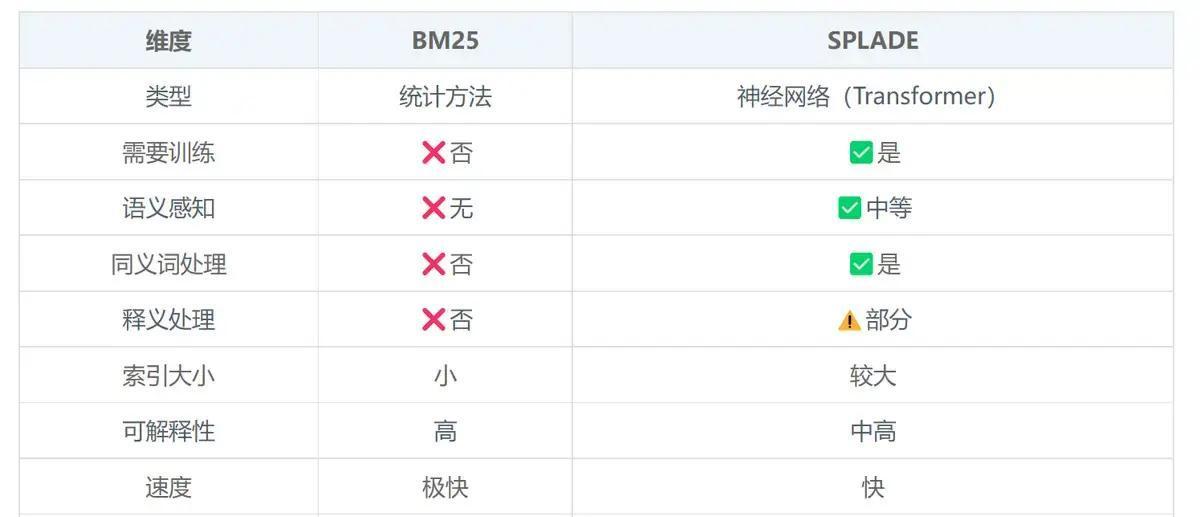
构建RAG系统时,大家经常会纠结:既然都要算文本相似度,为什么不直接用一个模型搞定,非要搞出Bi-Encoder、Cross-Encoder、SPLADE、ColBERT这么多花样? 核心原因其实就:召回率和精准率永远是对立的死敌,单个模型很难同时把百万级文档既捞得快又排得准。 先说Bi-Encoder,它最接地气也最常用。查询和文档分别丢进同一个编码器,各自吐出一个向量,然后简单比比余弦相似度就完事。因为文档向量可以提前算好扔进向量库,查询时只编码一次再快速ANN搜索,所以面对海量数据它速度飞起,扩展性极强。但缺点也很扎心:它只能粗略看整体意思,遇到否定词、逻辑转折、长句里的关键细节就容易翻车,召回的候选往往鱼龙混杂。 这时候就需要Cross-Encoder来救场。它直接把查询+文档拼接在一起喂给Transformer,输出一个0~1的相关性分数。因为全程token级深度交互,精准度基本是目前天花板级别。但代价也大:不能预计算,每次都要重新算,成本高到只能用来给几百上千个候选重排序,不可能直接扔给百万文档。 于是就诞生了“先粗捞再精排”的两阶段思路:Bi-Encoder负责高召回快速把Top-100~1000捞出来,Cross-Encoder再精排把真正相关的顶到前面。这套组合在2025~2026年的实际生产系统里依然是主流。 但事情还没完,稠密向量对专有名词、ID号、否定表达这些“硬匹配”场景天生吃力,SPLADE这种稀疏神经检索就站出来了。它学出一个带权重的词表分布,像升级版的BM25,既保留了关键词精确命中,又带点语义扩展能力。索引体积可控,解释性强,很多混合召回里都会加它一手。 而ColBERT则是目前最被看好的平衡选手。它不给整段文本打一个向量,而是每个token都独立编码,查询时用“晚交互”(late interaction)方式,让查询每个词去和文档所有词比对,取最大值再求和。这种细粒度匹配让它在复杂查询、长文档、领域专有表达上明显碾压普通Bi-Encoder,精度接近Cross-Encoder,但因为文档向量预计算+高效索引结构,速度和扩展性又远好于Cross-Encoder。 2025-2026年的最新趋势里,ColBERT(尤其是ColBERTv2和各种蒸馏/压缩变体)在生物医学、法律、金融等硬核领域已经多次刷出SOTA,各种开源工具(RAGatouille、PyLate)也让它落地门槛大幅降低。很多团队现在直接上混合第一阶段(BM25/SPLADE + Bi-Encoder)→ ColBERT晚交互重排的流水线,召回率高、精准度强、延迟还能接受。 :没有万能模型,只有合适的分工。想让RAG真正靠谱,就得学会用不同模型打配合拳,先用快的把人捞出来,再用准的把对的排到最前面。这才是规模化RAG系统的真实打法。