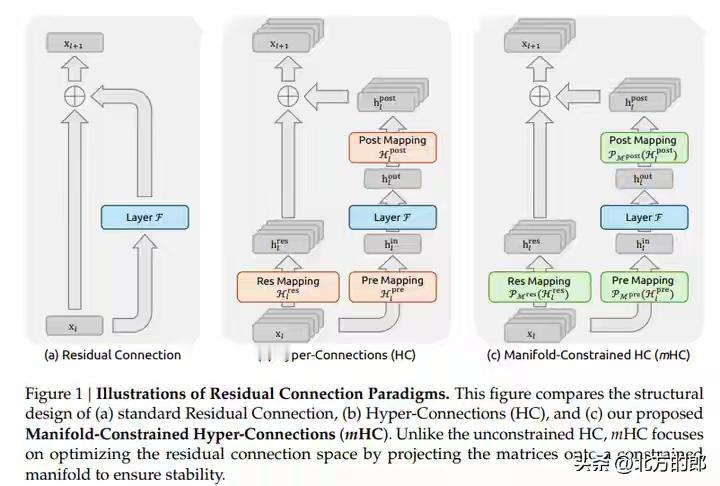
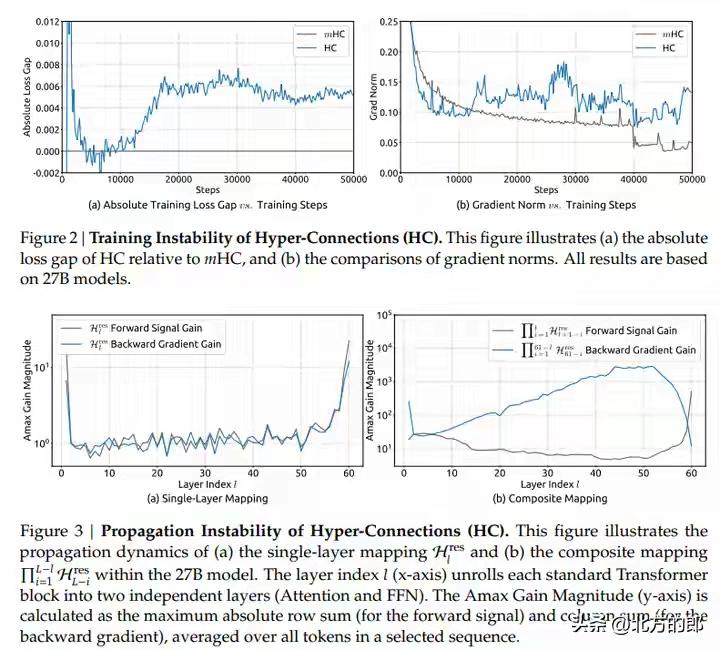
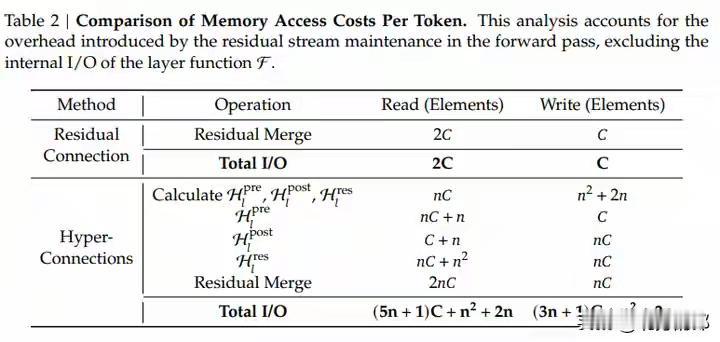
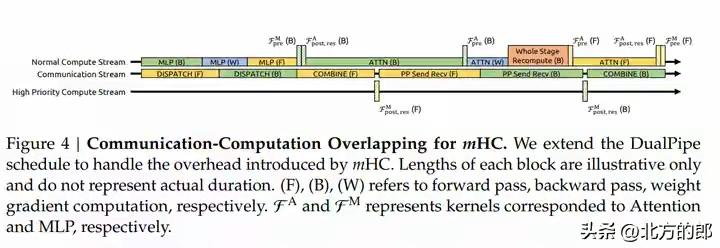
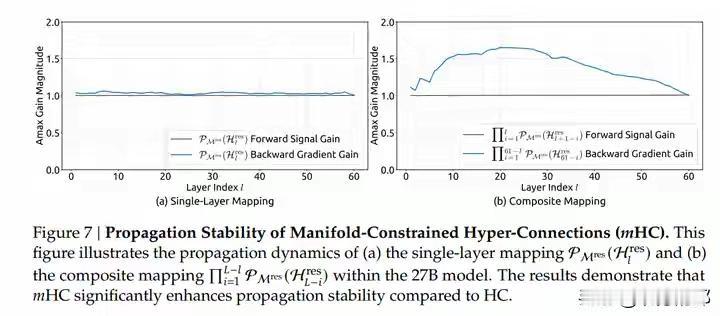
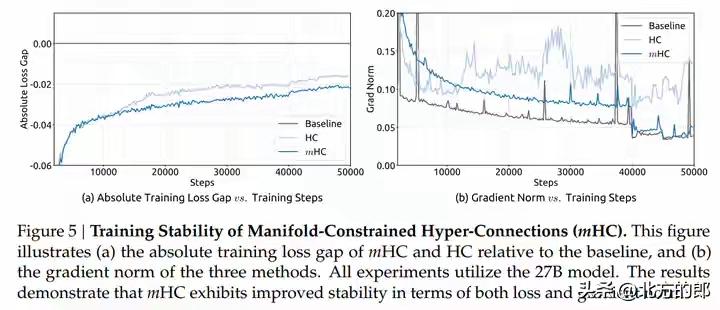
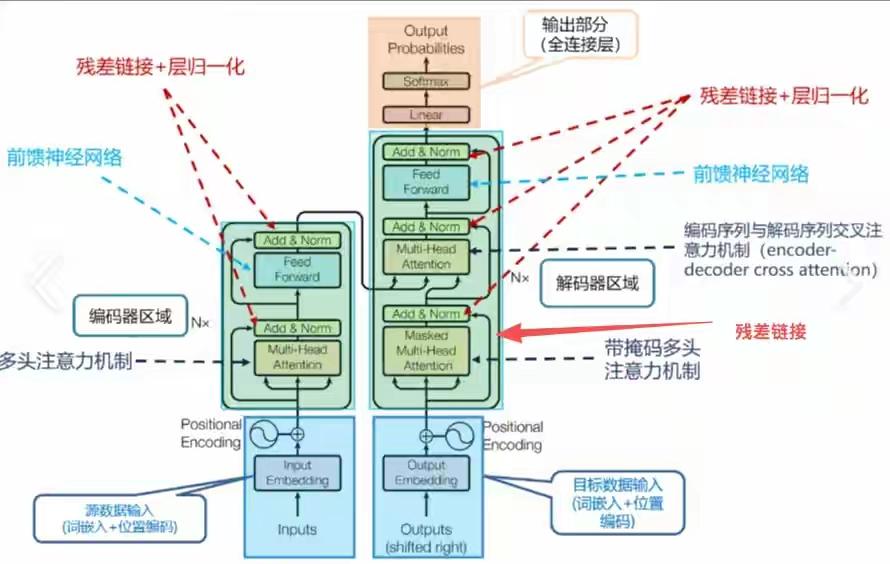
DeepSeek新年炸裂一击!仅用6.7%成本驯服AI“千层狂魔”,27B大模型训练稳如泰山,底层架构革命已至! 当全世界的AI实验室都在为堆叠更多参数、寻找更强大算力而疯狂内卷时,一个幽灵般的难题始终如达摩克利斯之剑高悬头顶:模型越深,越容易“走火入魔”。信号在千层神经网络中穿梭,稍有不慎便会失控爆炸,让数月训练心血瞬间崩盘。这不仅是技术的瓶颈,更是无数工程师深夜调试时最深的恐惧。 就在此刻,DeepSeek团队掷出了一篇看似平静却石破天惊的论文。他们没有选择蛮力硬刚,而是像一位高明的中医,直指病灶根源——那个让模型性能飙升却又随时可能自毁的“超连接”技术。原来,问题的核心并非道路不够宽,而是缺少了精密的交通规则。 他们给出的解药,充满了东方的哲学智慧:约束,是为了更大的自由。通过一套名为“流形约束”的数学框架,他们将那些肆意狂奔的信号,巧妙地限制在了一个名为“双重随机矩阵”的优雅空间里。这就像为狂野的江河修筑了坚固的河堤,水势依然浩荡,却再也不会泛滥成灾。 最令人拍案叫绝的,是这份“稳定”的代价,低到几乎可以忽略不计。仅仅6.7% 的额外训练开销!这意味着,各大厂动辄耗费数千万美元的算力集群,其潜力将被更安全、更充分地释放。这不是简单的修补,而是一次对深度学习根基的优雅重塑。 我们不禁要问,为何是DeepSeek做到了?这背后或许是一种截然不同的研发文化:不追逐喧嚣的噱头,而是沉入最底层的数学原理与工程细节。当别人在架构表面做花样文章时,他们选择潜入深海,去加固那条承载一切信息的“残差流”主干道。 这项名为mHC的技术,其意义远不止于稳定训练。它悄然改变了游戏规则:未来的模型进化,可能不再依赖于无休止地增加参数自由度,而在于为这些参数设计更精妙的“数学舞台”。从野蛮生长的拓荒时代,走向精心规划的精耕时代,这或许才是AI走向真正成熟的标志。 对于每一位AI从业者而言,这篇论文更像一剂清醒剂。它告诉我们,在追逐SOTA榜单的狂热中,那些最基础、最本质的稳定性问题,依然蕴藏着颠覆性的创新金矿。真正的突破,往往来自于对常识的重新审视与对本质的深刻洞察。 站在2026年的开端回望,Transformer架构统治已近十年。人们一直在问:下一代基础模型是什么?mHC或许给出了一个方向性的提示:改变层与层之间简单叠加的“线性思维”,引入更丰富的拓扑连接与智能路由,让信息在模型中像智慧一样流动起来。 这不仅仅是一篇论文,这是一个信号。它宣告着,中国AI团队不仅能在应用赛道上飞奔,更能在最硬核、最底层的原始创新上,提出引领世界的关键思想。当技术的方向盘开始注入深刻的数学思想与工程美学,未来的旅程,更值得期待。 (来源:综合自DeepSeek官方论文《mHC: Manifold-Constrained Hyper-Connections》、相关技术社区解读及行业分析) AI突破 大模型训练