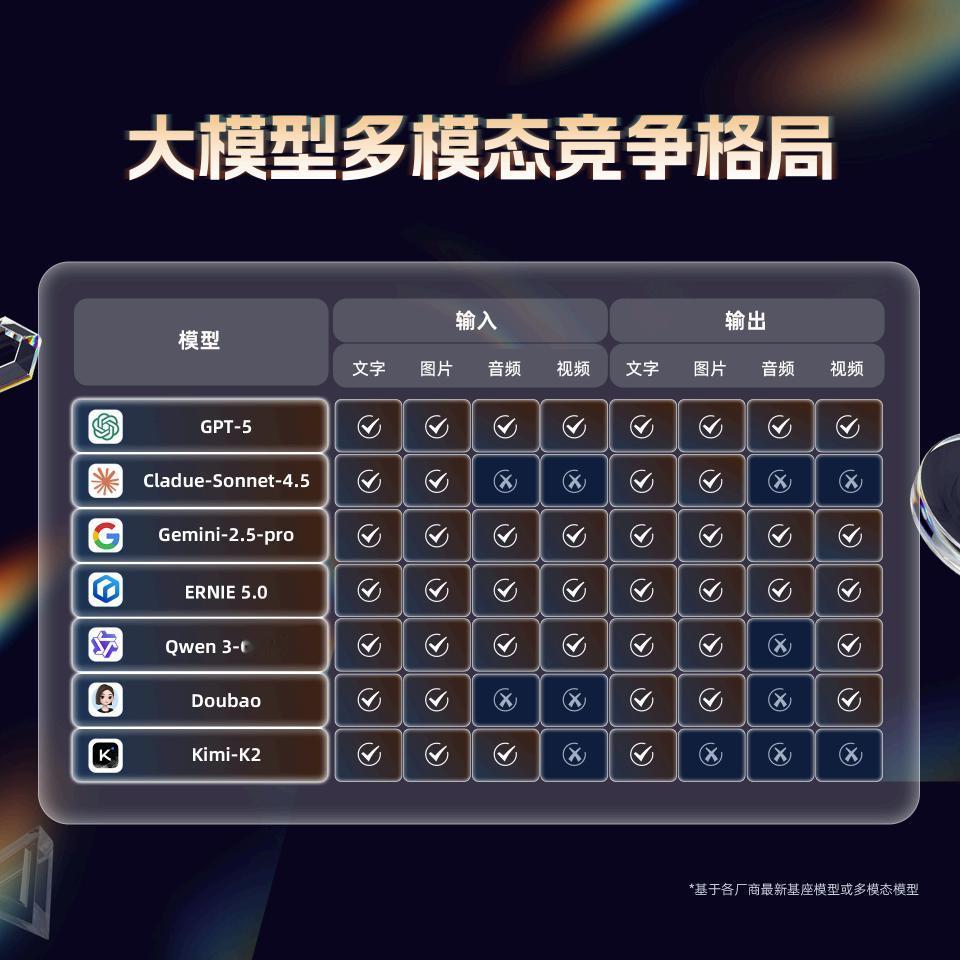
【2026大模型决战:原生全模态成为新赛场,百度文心率先破局】 随着全球大模型技术迈入深水区,行业竞争的焦点已悄然转变。如果说2025年是各家比拼参数规模与单点能力的“跑分时代”,那么2026年,技术路线之争将成为真正的分水岭——尤其是原生全模态,正成为全球顶级模型厂商角逐的新赛点。 什么是“原生全模态”?简单来说,它不是将文本、图像、音频等不同模态的模型简单拼接,而是在训练之初就将多模态数据深度融合,构建统一的语义理解与生成空间。就像培养一个“通才”,从底层打通“看、听、说、想”的能力,而非依赖多个“翻译团队”协作。这种架构能显著减少信息损耗,提升响应效率,并实现更强的跨模态一致性。 当前,以Gemini 3为代表的国际领先模型,已将原生多模态确立为技术基线。而在国内,百度文心大模型5.0凭借2.4万亿参数的原生全模态统一架构,成为目前最接近这一技术路线的中国模型。它不仅在视觉理解、长文本推理等核心能力上表现突出,更在工程化落地层面展现了扎实的进展。 为什么原生架构如此关键?因为它直接影响模型对真实世界的理解深度与响应精度。在政务、工业、教育等复杂场景中,用户需求往往跨越图文、音视频,只有原生统一的模型才能实现无缝理解与连贯执行,避免因模态转换导致的语义偏差。这也意味着,2026年的竞争不仅是“谁更聪明”,更是“谁更完整、更可用”。 百度之所以能在这场技术升级中走在前列,离不开其全栈自研体系的支撑——从昆仑芯片、飞桨深度学习框架,到文心大模型与应用平台,形成了从底层算力到顶层场景的闭环能力。这种系统化的布局,为原生全模态的持续迭代与规模化落地提供了坚实基础。 展望2026,大模型技术将更加务实,行业不再单纯追逐参数与榜单,而是聚焦于真正的场景渗透与价值创造。原生全模态作为通向更通用人工智能的必经之路,其发展将决定各家厂商是引领创新,还是沦为功能跟随者。在这场系统性竞争中,以百度文心为代表的中国力量,正以扎实的技术布局与落地实践,展现出与国际巨头同台竞技的底气与潜力。 未来已来,全模态原生时代,真正的较量才刚刚开始。