[LG]《Representation-Based Exploration for Language Models: From Test-Time to Post-Training》J Tuyls, D J. Foster, A Krishnamurthy, J T. Ash [Microsoft Research NYC & Princeton University] (2025)
基于表示的探索策略:从推理时到后训练,提升语言模型能力
🔍 研究背景:
强化学习(RL)有望让语言模型(LLM)自主发现新技能,但现有RL方法多是在“磨锐”已有能力,难以真正发现全新行为。本文重点探讨如何通过“刻意探索”激励模型挖掘多样且新颖的行为,利用预训练模型内部表示指导探索。
🌟 核心贡献:
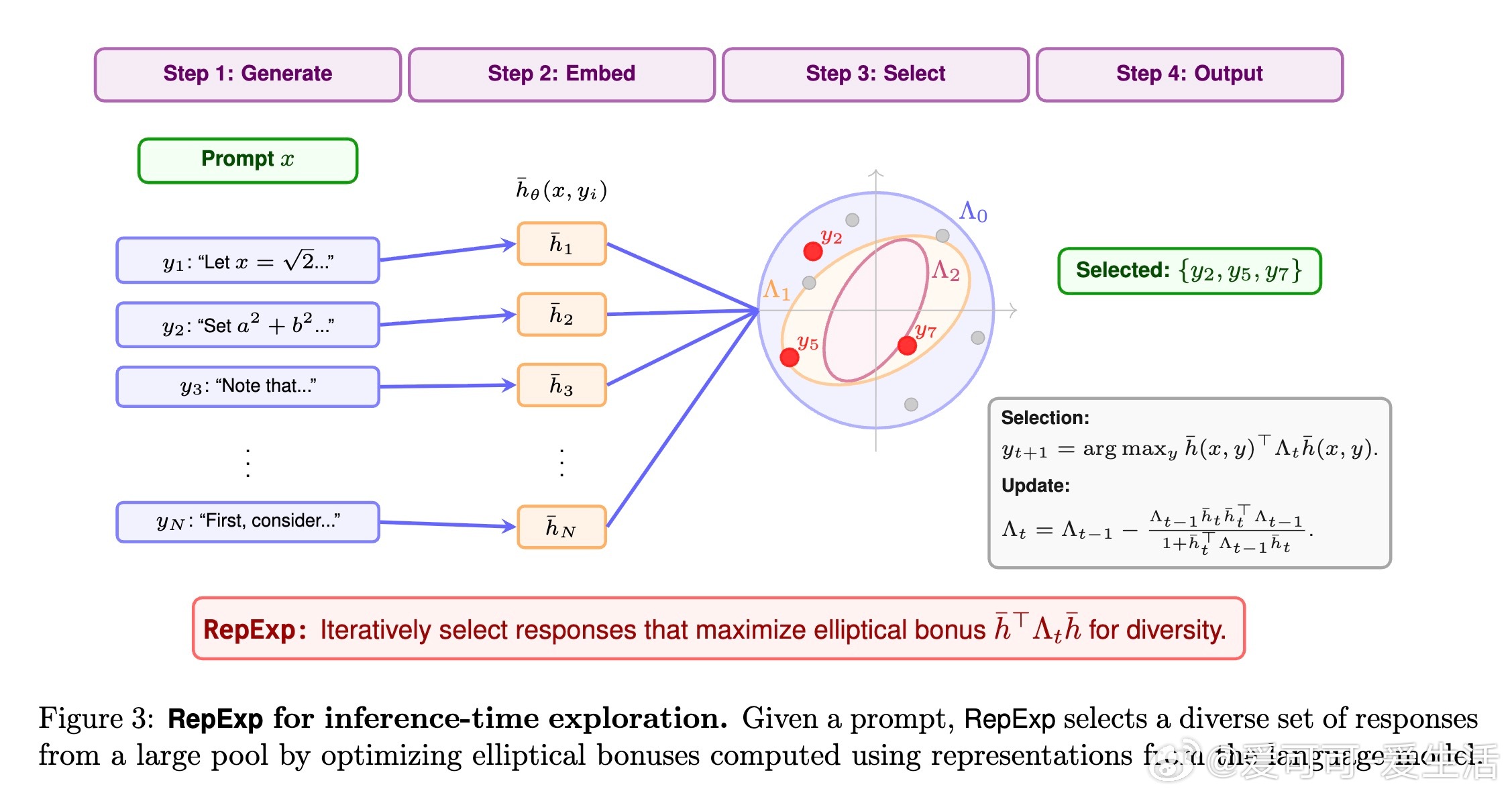
1️⃣ 推出基于语言模型隐藏状态的表示驱动探索奖励(rep-exp),简单高效,无需额外训练辅助网络。
2️⃣ 在推理时(inference-time)和后训练(post-training)两阶段验证该探索策略,均显著提升解题多样性和准确率(pass3️⃣ 推理时探索能提升“验证器效率”(samples-to-correct减少50%以上),且效果随模型规模增强而显著提升。
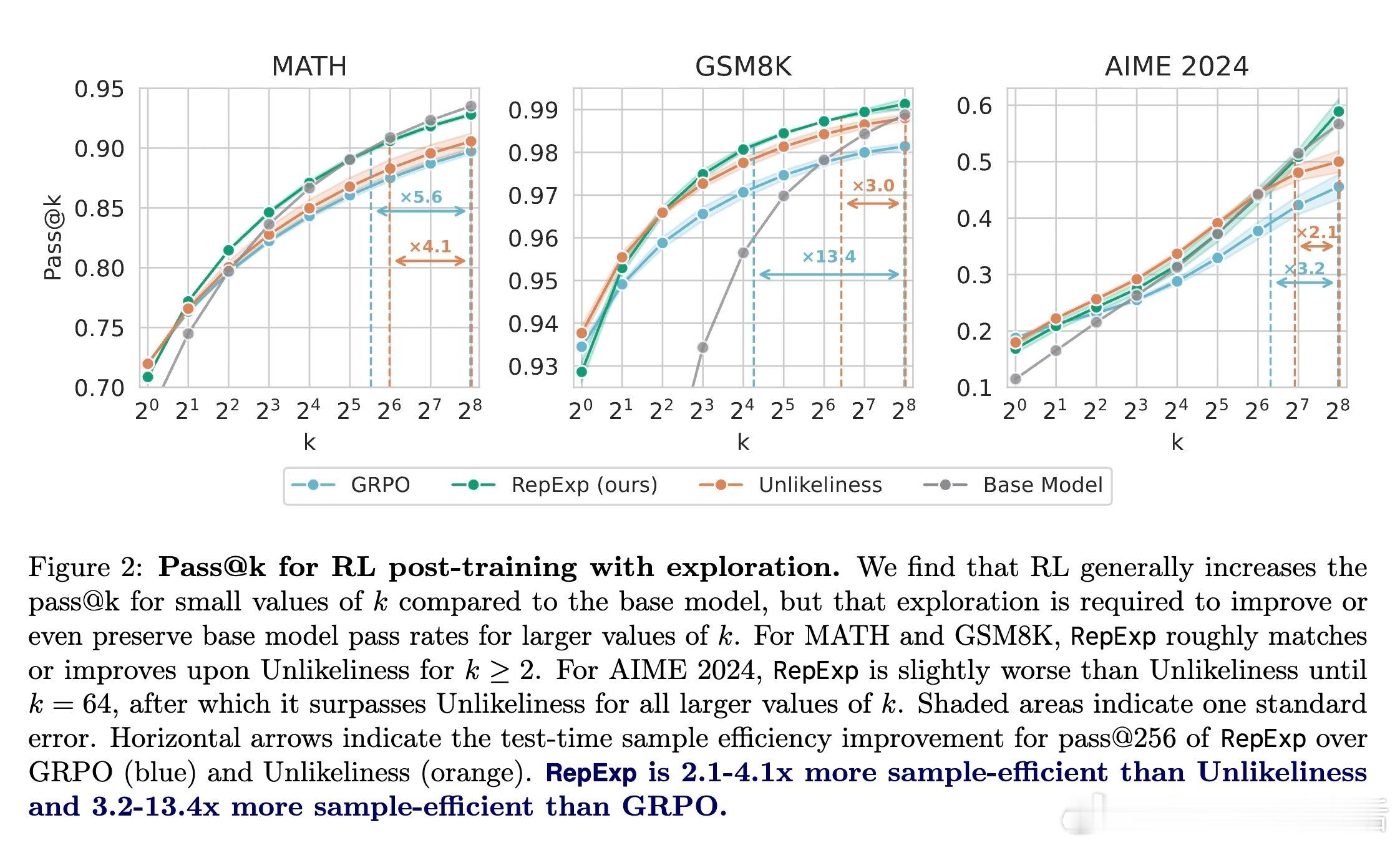
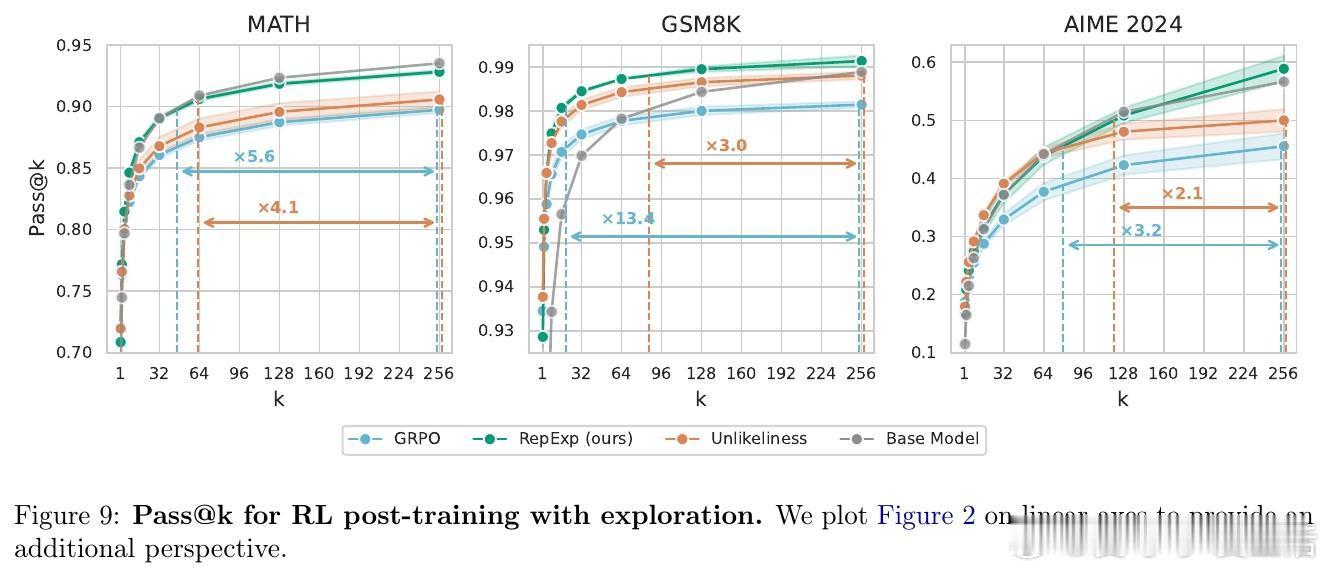
4️⃣ 后训练中结合RL,rep-exp方法有效避免传统RL出现的“多样性崩溃”现象,样本效率提升3-13倍。
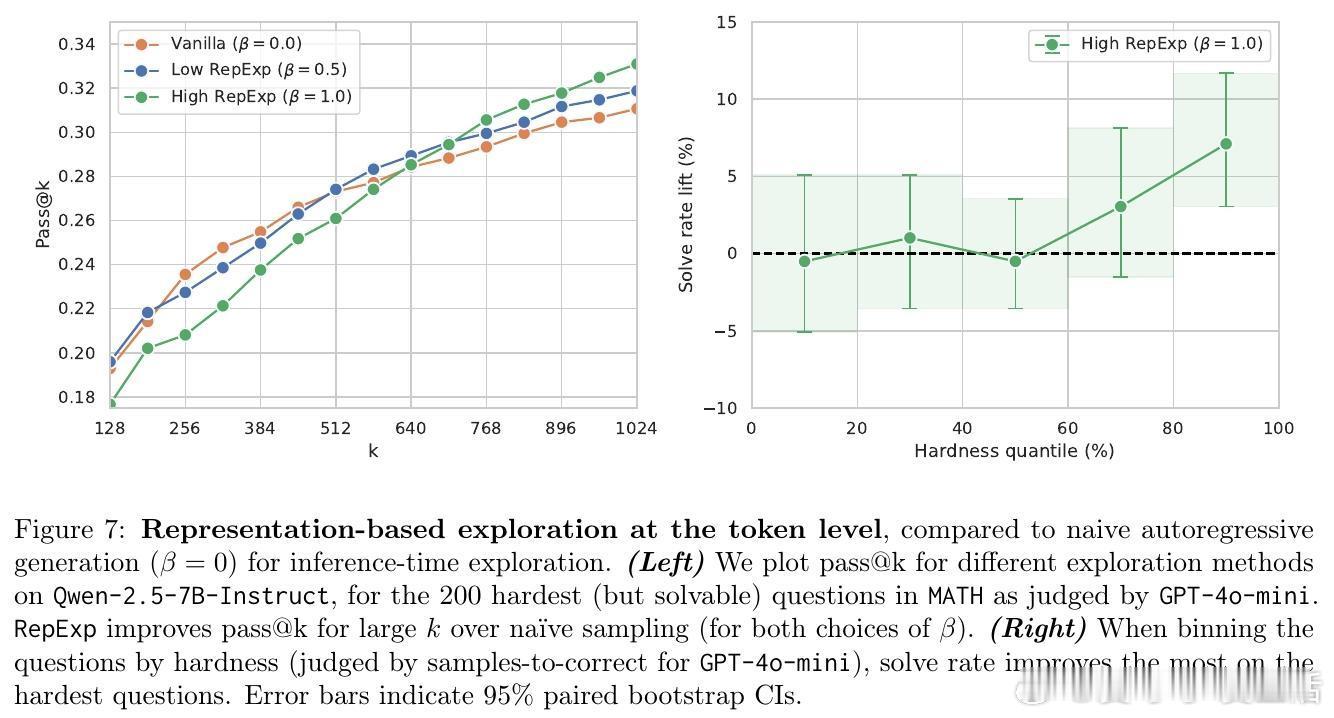
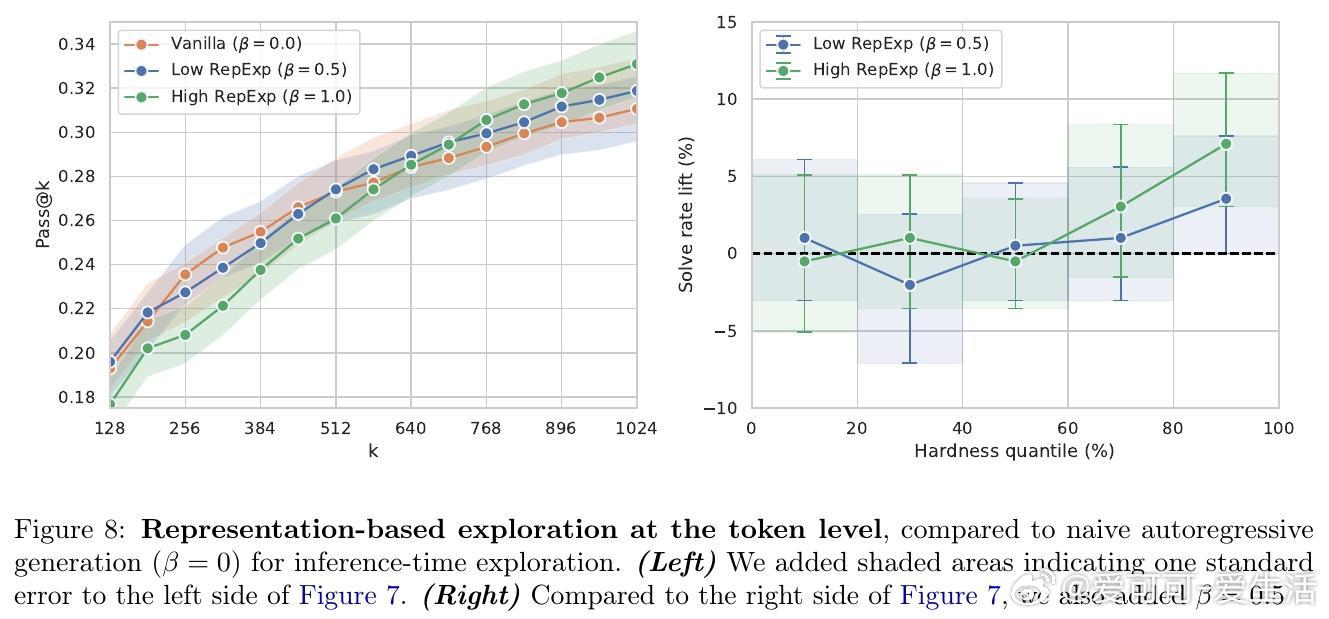
5️⃣ 初步探索将探索奖励融入自回归生成过程,亦带来困难样本上解题率提升。
⚙️ 技术细节:
- 代表性奖励基于线性代数中的椭圆奖金(elliptical bonus),通过计算生成文本在预训练模型隐藏层的特征向量的“新颖性”来激励探索。
- 推理时方法(RepExp)先采样大量候选回答,再迭代选择最能增加多样性的子集。
- 后训练中,将该奖励直接加到RL的回报函数,促进模型学习更广泛的策略空间。
- 实验使用了Qwen、Phi、Llama、Mistral等多种现代大模型,涵盖数学推理、代码生成等多样任务。
📈 实验亮点:
- MATH、GSM8K、MBPP+等数据集上,RepExp降低寻找正确答案的平均样本数,特别在难题上优势明显。
- 大规模模型(如Qwen-2.5-14B)在多任务上,推理时探索提升验证效率超50%。
- 在后训练阶段,RepExp在AIME 2024数学测试上,pass- 对比多种生成采样策略,RepExp在绝大多数情况下均优于随机采样。
- 自回归生成阶段的探索奖励策略对困难问题尤其有效。
💡 研究意义:
本工作明确表明,利用预训练模型内部表示设计的探索奖励,是推动语言模型跨越“能力磨锐”瓶颈、发现新行为的有效途径。探索策略不仅提升了效率,还保障了多样性,是未来语言模型强化学习的重要方向。
🔮 未来方向:
- 结合更大规模RL训练,融合其他提升推理能力技术。
- 优化自回归生成中的探索策略,降低计算资源消耗。
- 拓展到无可验证奖励环境,研究探索与防止奖励作弊的平衡。
🌐 论文及代码链接:rep-exp.github.io
📄 原文地址:arxiv.org/abs/2510.11686
语言模型 强化学习 探索策略 机器学习 AI研究 自然语言处理