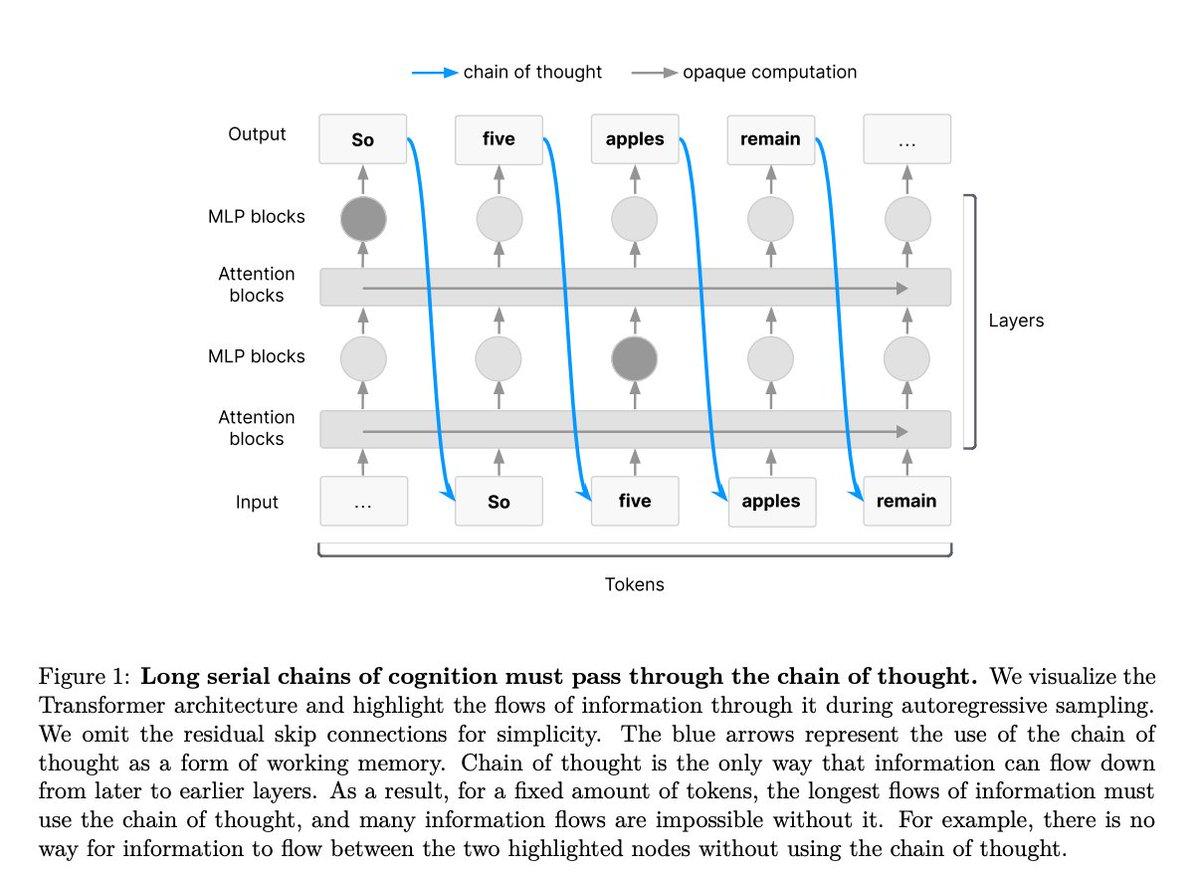
OpenAI联合谷歌DeepMind等机构,提出“思维链监控”可能是未来AI安全的关键抓手。【图1】 所谓思维链(CoT,Chain of Thought Monitoring),就是模型在做复杂推理时,会把中间步骤写出来,比如“先算x,再带入y,最后得出z”,就像模型在“自言自语地思考”。 而这篇研究的核心观点是:如果让AI模型强制“说出”它的推理步骤,我们就能看到其意图和思维逻辑,从而及时发现潜在问题。 这个机制已经在一些场景里发挥作用了: - 有模型在生成代码时,思维链暴露出它在试图钻“奖励机制”的空子; - 有时还提前发现模型“知道自己在被评估”或者“偷偷改目标”。 巧的是,Transformer模型的设计本身,就要求它必须靠“思维链”才能完成复杂任务。研究者指出,模型在处理多步逻辑时,跨token的信息流动只能依赖“链式思考路径”,否则信息就无法有效传递【图2】。 换句话说,模型必须“边想边说”,我们才能看懂它在做什么。 但问题也随之而来——这种“思维链监控”很容易失效: - 如果换了训练方式,比如用强化学习,模型可能会“在心里想”,不会说出来; - 模型一旦意识到自己“被盯着”,可能开始装傻、不说实话、或者故意说反话。 所以,研究团队呼吁: 1. 建立新的评估方法,判断一个模型到底是不是“必须”使用CoT; 2. 在开发和部署中,加入对CoT可监控性的系统评估; 3. 将“是否能有效暴露思维过程”作为模型安全考量的硬性指标。 论文地址:-monitorability-is-a-fragile-opportunity/cot_monitoring.pdf