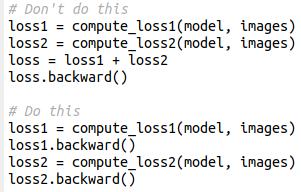
一个简单的PyTorch技巧,让GPU内存占用减半! 网友Gabriele Berton分享了一个他多年来一直在使用的小技巧,能够大幅提升内存效率,核心在于:逐个损失反向传播。 这个技巧的关键在于:与其把所有损失加起来再一次性进行反向传播,不如对每个损失单独进行反向传播。 【图1】 这样做的好处是,每次反向传播后,对应的计算图就会立即释放,从而节省大量内存。 也就是说,相比较于: loss1 = compute_loss1(model, images) loss2 = compute_loss2(model, images) loss = loss1 + loss2 loss.backward() 像这样优化,更能节省内存 loss1 = compute_loss1(model, images) loss1.backward() loss2 = compute_loss2(model, images) loss2.backward() 不过,这个技巧只适用于存在多个独立损失函数的情况。损失函数越多,节省的 GPU 内存就越明显。 而且,如果损失函数之间相互耦合(例如,一个损失的计算依赖于另一个损失的中间结果),那么这个方法就不适用了。 这里给出一个耦合损失的反例,此时该方法将失效【图2】 这个方法为什么能省内存呢? 深度学习训练过程中,计算图是消耗 GPU 内存的大户。 当你对一个损失执行 backward() 后,PyTorch会立即释放与该损失相关的计算图。 通过分步反向传播,每次处理完一个损失就释放一部分计算图,从而有效降低峰值内存占用。 在某些情况下,当不同的损失函数需要处理不同的输入数据时,分步前向传播(以及随后的分步反向传播)甚至是唯一可行的方案。 大家可以亲自尝试一下~