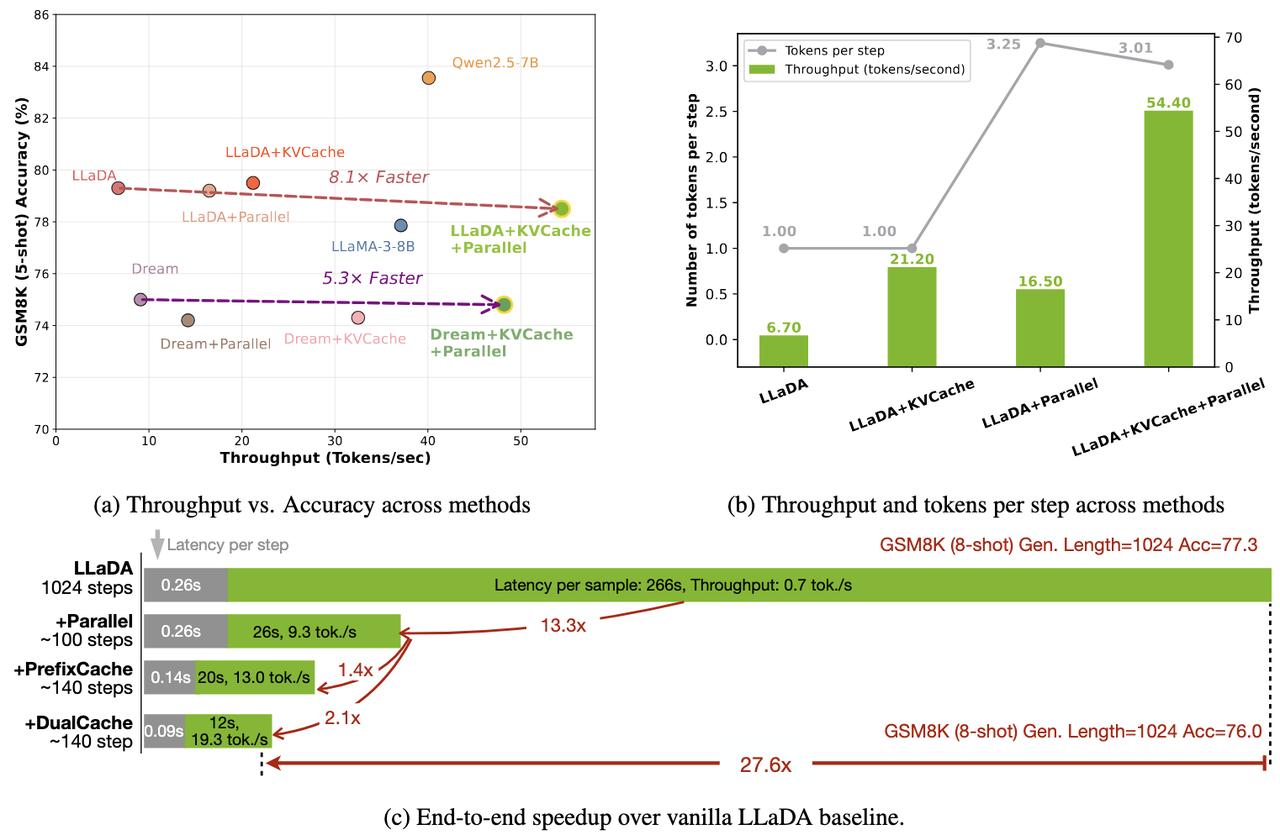
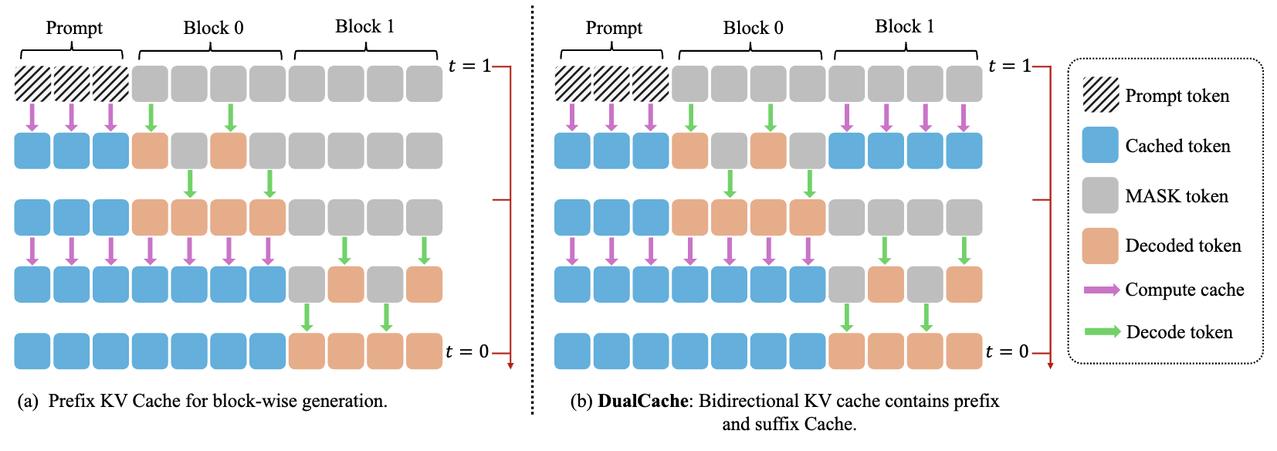
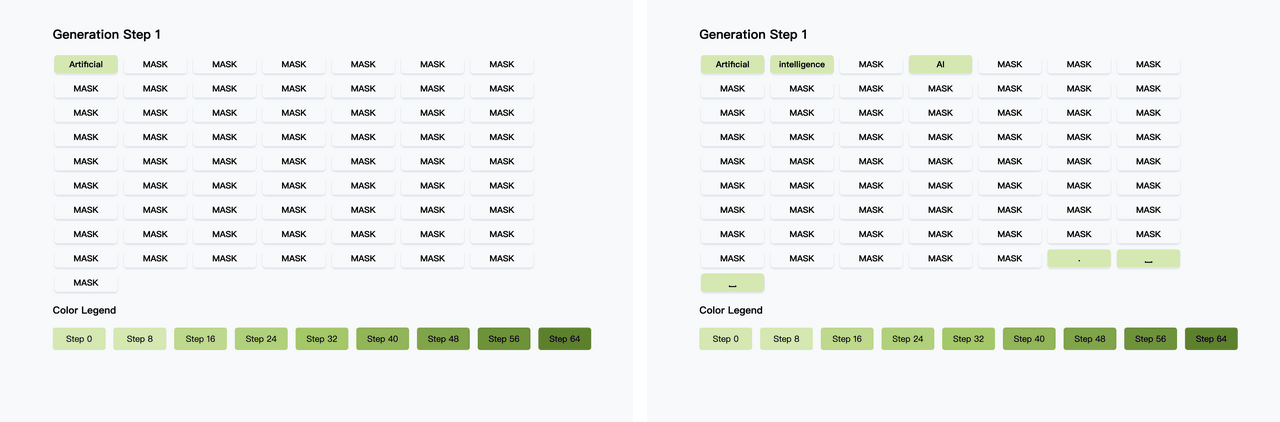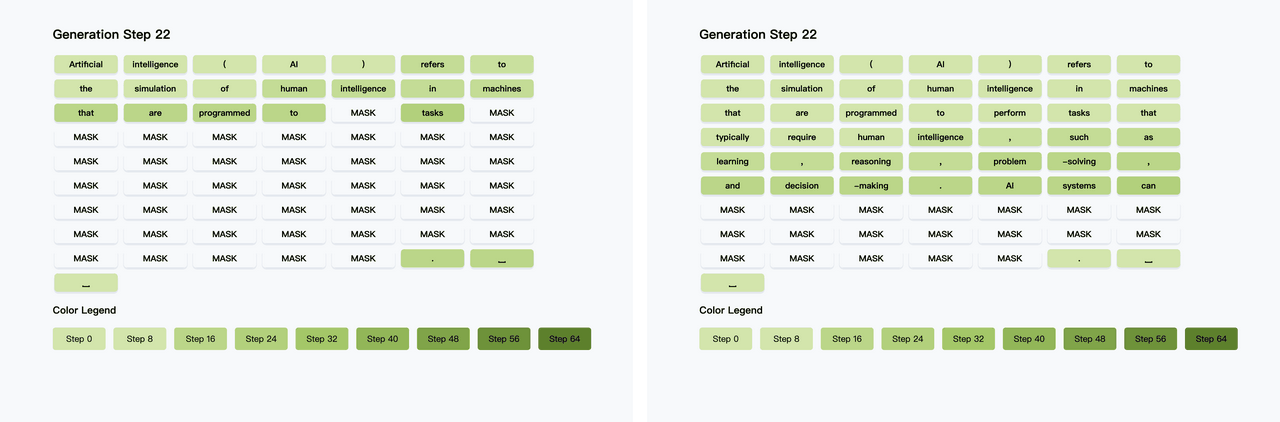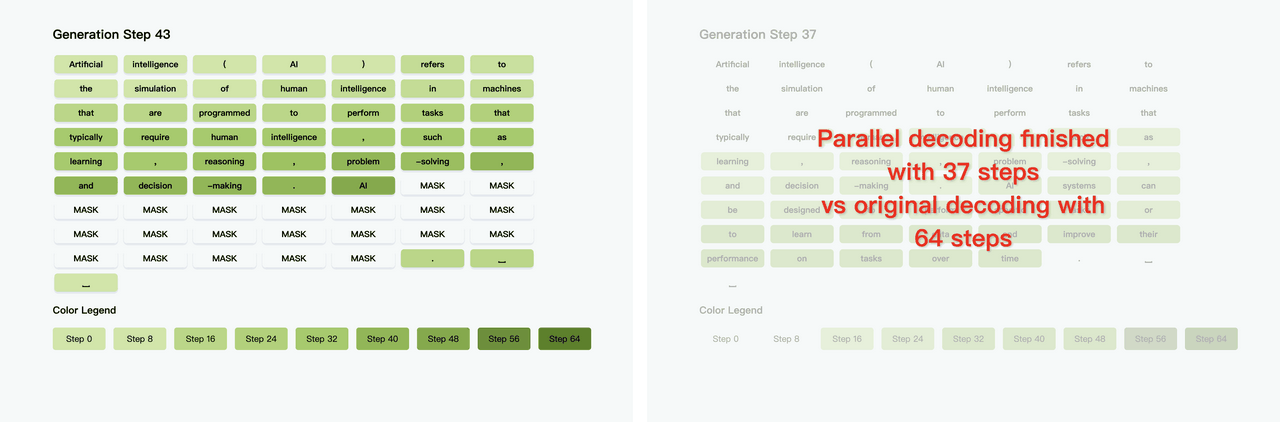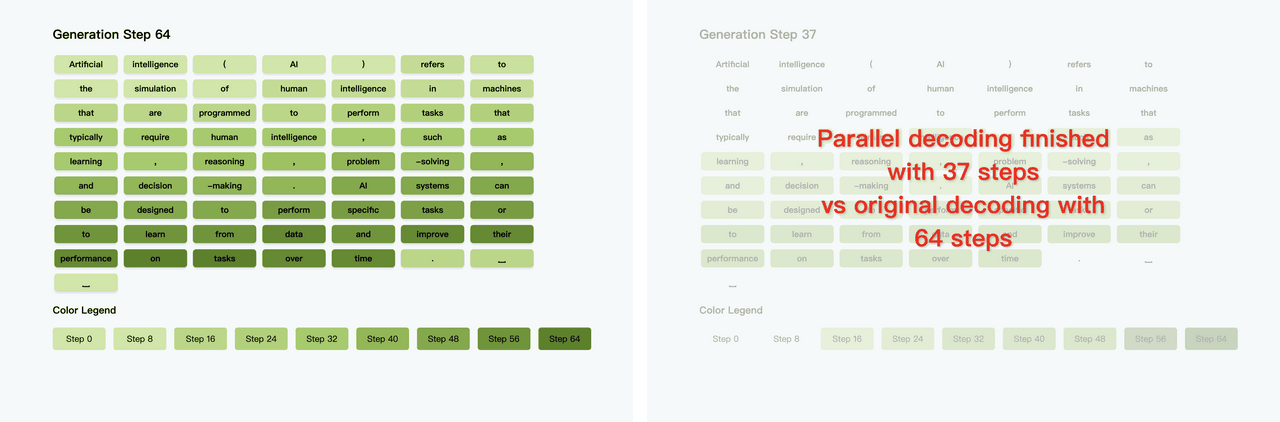
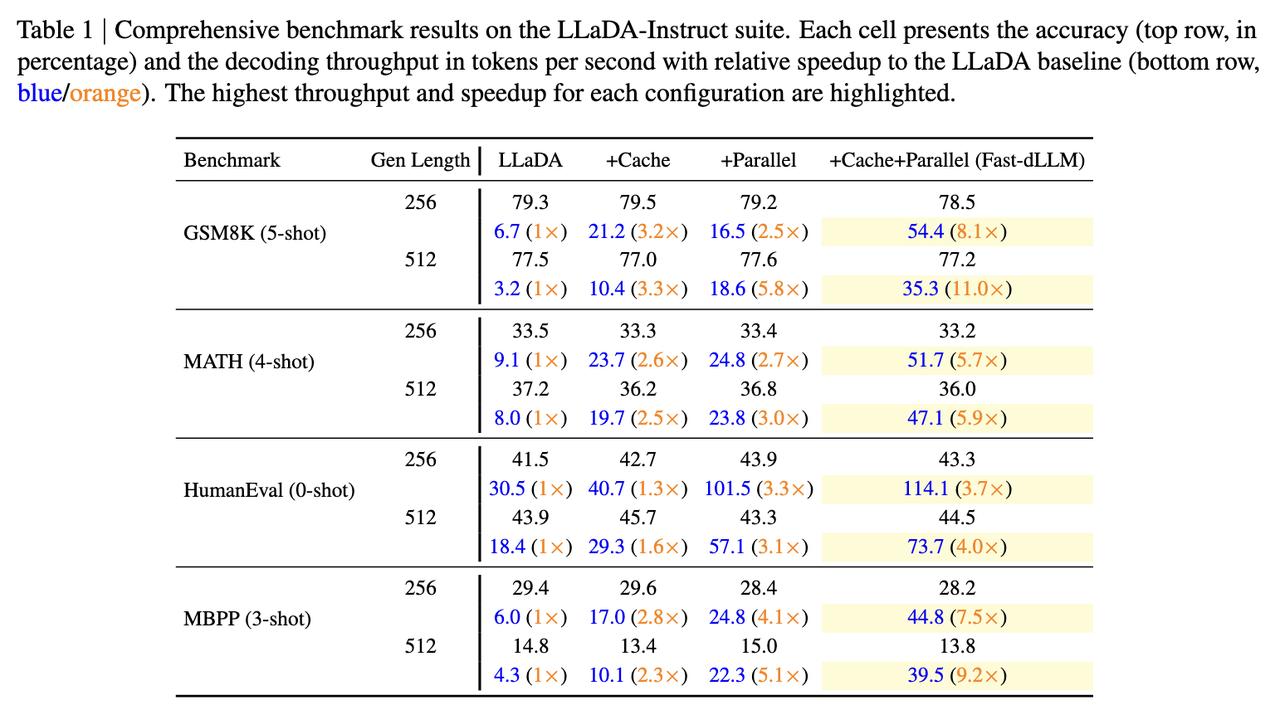
Diffusion LLM(扩散大语言模型) 是一种新兴的语言建模方法,它融合了扩散模型(Diffusion Model) 与传统的大语言模型(LLM) 架构。 不同于自回归模型逐词生成,扩散模型可以同时生成整体结构,更利于保持句子连贯性,适合诗歌、复杂文案。 然而,扩散模型通常需要更多训练步骤,经历几十到上百步去噪才能生成文本,相比Transformer那种“一步出一个词”的方式慢很多。 但最近港大、英伟达和MIT联合提出了Fast-dLLM,实测让这类模型加速多达27.6倍,关键是:完全不需要重新训练。【图1】【图2】 Fast-dLLM的核心优化可以拆成两块: - KV Cache机制重做了:针对双向注意力的Diffusion LLM,Fast-dLLM设计了块级的Key-Value缓存结构,可以缓存多个token的激活值,大幅减少重复计算。而进阶版DualCache,甚至连还没解码的后缀token也能缓存,提高复用率。【图3】 - 并行解码不再盲猜:Diffusion LLM原本多token解码精度不稳,是因为强行假设token之间独立。Fast-dLLM提出“基于置信度”的并行解码,只在高置信的token上并行生成,其他保留MASK,下一步再解。实测可以从原本60多步压缩到37步完成生成,既快又稳。【图4】 令人惊喜的是,这两套机制可以组合使用: - 单独用KV Cache,提升2~3.6倍吞吐量 - 单独用并行解码,额外提升1.5~2倍 - 合并使用,GSM8K上加速11倍,MBPP上加速9.2倍 除了快,该方法的准确率也有保障。比如GSM8K任务中,准确率下降不足2%,仍保持在77%以上。【图5】 这项方案已经在多个开源Diffusion LLM上验证过,包括LLaDA和Dream模型。适配性强,性能涨幅也更明显出现在“长序列+多shot”的任务上,比如1024 token+8-shot推理。【图6】 感兴趣的小伙伴可以点击:-dLLM/