#Seed2.0正式发布# 据“字节跳动Seed”:大语言模型驱动的产品已深刻融入我们的生活。过去一年多,Seed 开发的 LLM 模型系列已支持豆包等拥有上亿用户的 C 端产品,同时,我们也注意到,随着 Agent 时代到来,LLM 将在现实世界的复杂任务中发挥更大作用:比如参与科学研究,支持复杂软件开发,LLM 甚至可以基于上下文自主学习,完成各类具有经济价值的任务。
在这个关键节点,我们很荣幸地介绍最新 Seed2.0 系列,它们围绕大规模生产环境下的使用需求做了系统性优化,旨在帮助突破真实世界中的复杂任务。
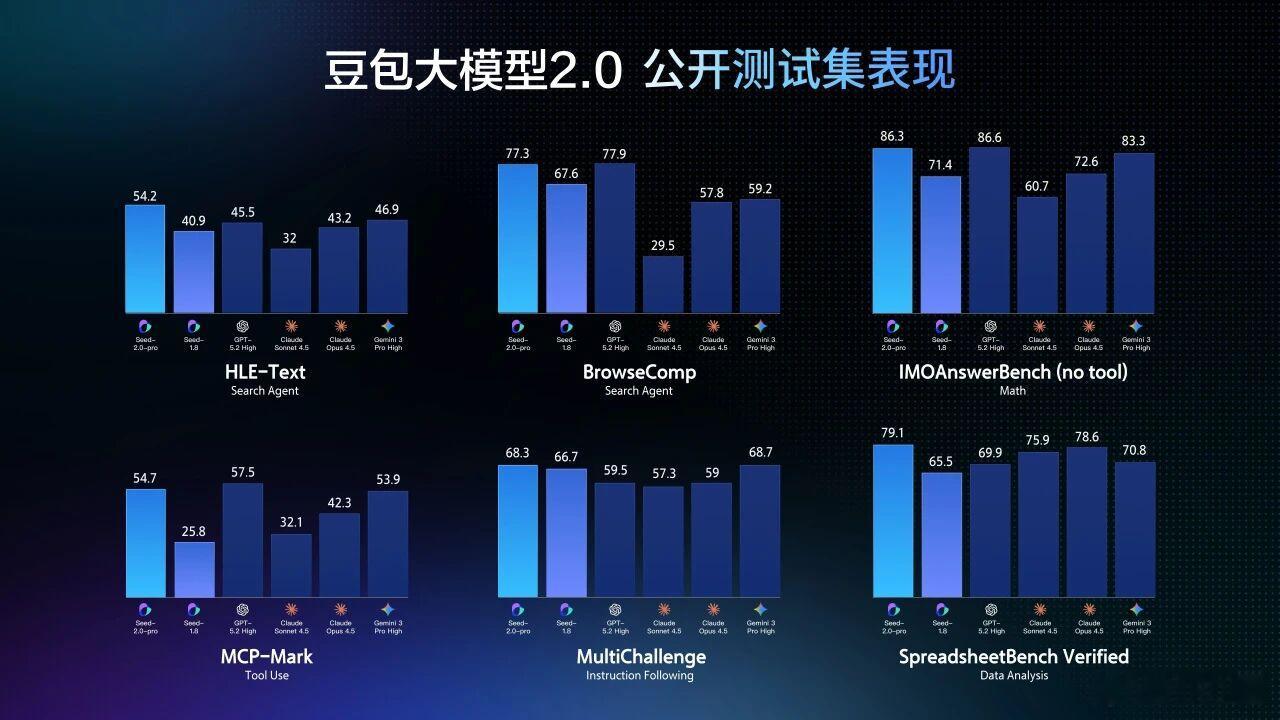
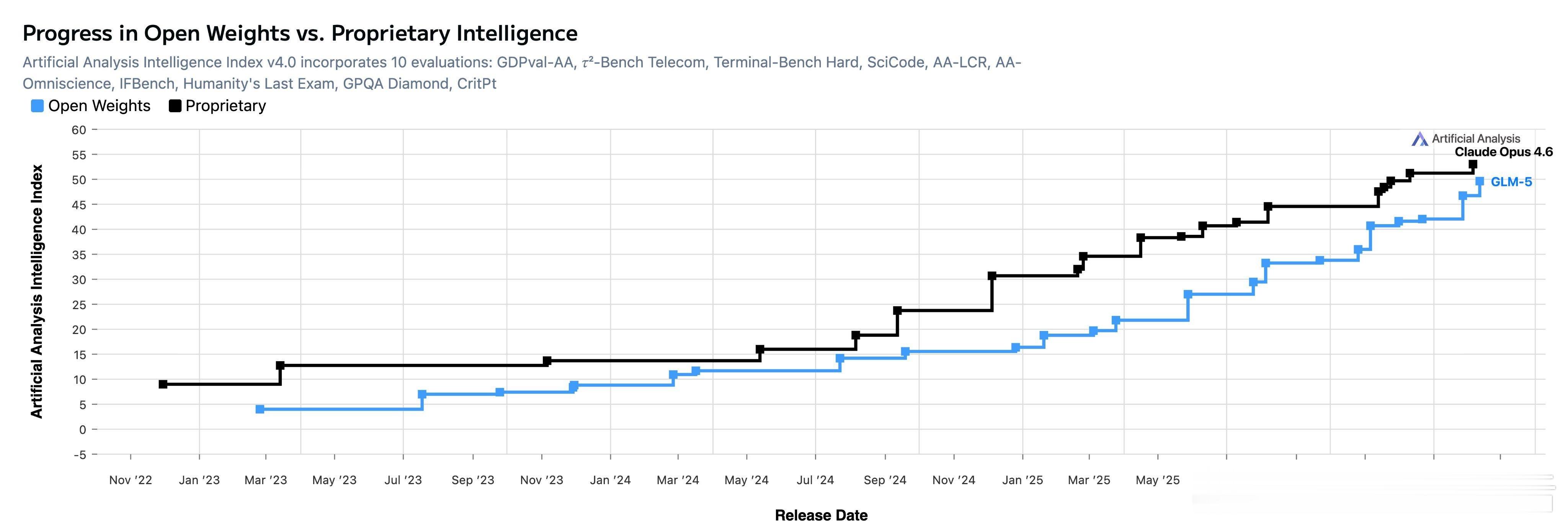
通过分析 Seed 通用模型在 MaaS 服务中的调用情况,我们发现,最高比例的需求为处理混杂图表、文档等非结构化信息的知识内容,企业往往要求模型先做“读得多、想得多”的任务,再进入复杂且专业的流程型工作,对模型的长内容理解和多步任务执行能力要求越来越高。
基于真实使用场景,Seed2.0 系列重点在以下方面进行了优化:
更稳健的视觉与多模态理解:Seed2.0 强化了视觉感知与推理能力,对复杂文档、表格、图形、视频内容的解析水平显著提升,视觉信息处理更精准。
更可靠的复杂指令执行:Seed2.0 提升了指令遵循和推理表现,并强化了对多约束、多步骤、长链路任务的理解与执行能力,已具备支撑高价值任务的能力基础。
更快速、更灵活的推理选择:Seed2.0 提供 Pro、Lite、Mini 三款不同尺寸的通用 Agent 模型,以及专门的 Code 模型,覆盖不同的场景需求,供企业和开发者选择。
除了更好地支持生产级需求,Seed2.0 还致力于提升模型智能上限。目前,Seed2.0 已能从解决奥林匹克竞赛类问题迈向支持研究级的推理任务。比如,Seed2.0 可尝试探索埃尔德什级别的数学问题,也可完成部分科学相关任务的编程工作,进一步突破机器智能的边界。
Seed2.0 Pro 和 Code 模型已分别在豆包 App 和 TRAE 上线,同时,Seed2.0 全系列模型 API 已同步上线火山引擎,欢迎大家体验、反馈。网页链接