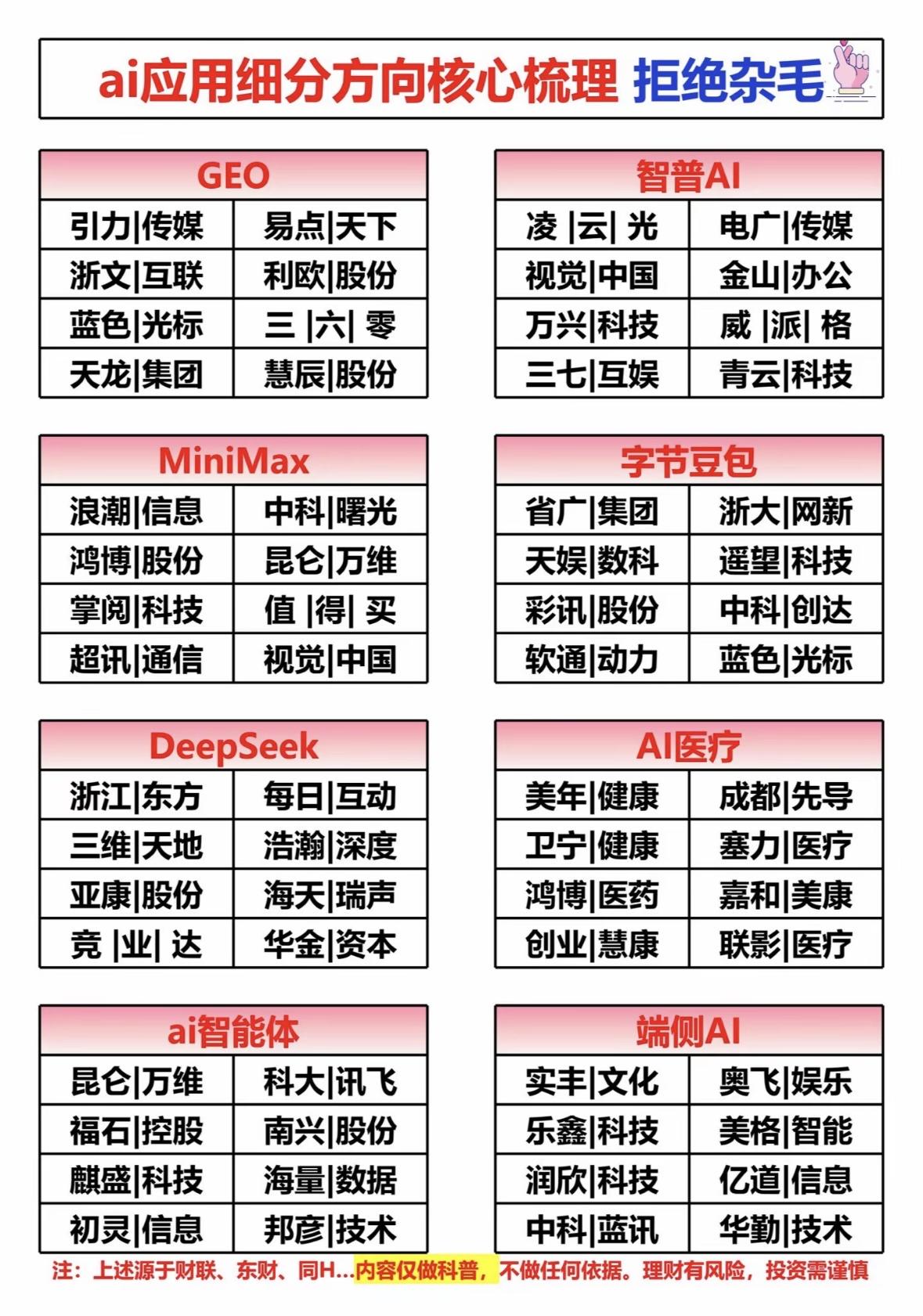
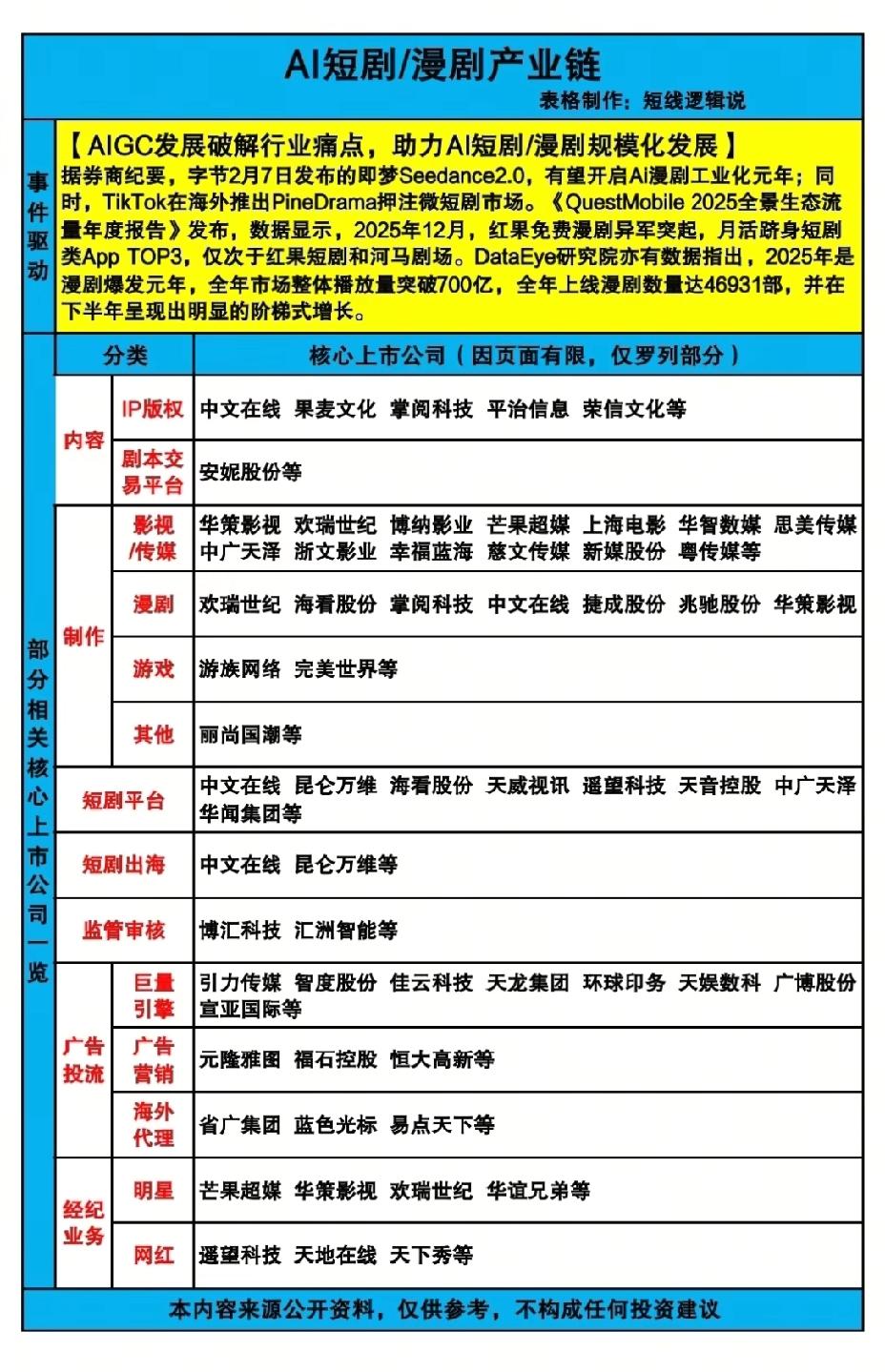
2月9日晚,新加坡联合早报一则报道:字节跳动的Seedance2.0 AI视频生成模型爆红,有网红博主担心自己“被训练”,让本就争议不断的AI语料版权问题,再次被推到聚光灯下。 这场景不算新鲜,每回生成式AI模型火起来,版权争议就像按捺不住的潮水,总会漫过讨论的堤岸。说到底,核心问题从没变过:当创作不再是独立作品的诞生,而是数据分布与模型生成的结果。 老一套的版权框架,就像不合脚的旧鞋,注定走不远。这是全球AI行业都得面对的制度坎儿,不是中国一家的难题。字节跳动Seedance2.0走红,带出版权讨论本是常情。 可有些媒体的姿态,却透着明显的双标。西方同类技术有突破,就被捧成“文明之光”,说是什么“造福人类”的创举;轮到中国AI追上来,稍稍展露锋芒,立刻被扣上“备受质疑”的帽子。 刻意把争议放大,把技术价值弱化,只盯着问题不谈共性,只揪着中国不放却无视全球现状。这种选择性叙事,哪里有半点客观公正? 说白了,就是戴着有色眼镜看中国科技进步,故意绕开AI时代最该谈的——版权规则需要全球一起重构这个核心命题。 老话说“一视同仁”,可在AI发展这事上,有些声音总难做到。 就拿AI绘画来说,国外模型刚出来时,铺天盖地的是“艺术革命”的赞美,即便涉及版权争议,也多被轻描淡写说成“成长的烦恼”。 轮到中国团队做出能打的模型,质疑声就陡然拔高,仿佛版权问题是中国AI独有的原罪。这种双重标准,与其说是对版权的较真,不如说是对中国科技崛起的不适应。 其实谁都清楚,AI训练离不开海量数据,其中难免涉及既有作品的片段。怎么界定合理使用?如何平衡创作者权益与技术进步? 这些问题,美国的OpenAI在面对ChatGPT版权诉讼时头疼,欧洲的AI公司在训练数据合规上也犯难,中国企业自然也会遇到。这是技术突破必然伴随的制度探索,就像汽车刚发明时,没人知道该怎么定交通规则,只能在实践中一点点磨出来。 Seedance2.0的走红,恰恰说明中国AI在视频生成领域的进步。从文本到图片再到视频,技术门槛在不断被突破,这背后是无数工程师的心血,是中国科技企业在前沿领域的奋力追赶。 这样的进步,值得被正视,而不是被偏见裹挟的争议淹没。 版权问题当然要解决,但得放在全球共通的语境里谈。该建立新的授权机制?还是该明确数据使用的边界? 这些都需要各国坐下来,一起商量着定规矩。而不是一边对自家技术的问题睁一只眼闭一只眼,一边对别人家的进步鸡蛋里挑骨头。AI浪潮滚滚向前,谁也挡不住。 中国AI的发展,不是为了给谁添堵,而是为了在技术革命中不落下,为了让创新成果能惠及更多人。面对版权这类新问题,我们不回避,也期待全球能有更公平的讨论环境。 毕竟,技术的进步,从来不是某一方的独角戏,而是全人类共同的探索。少些双标,多些协作,才能让AI真正成为推动文明进步的力量,而不是撕裂共识的工具。