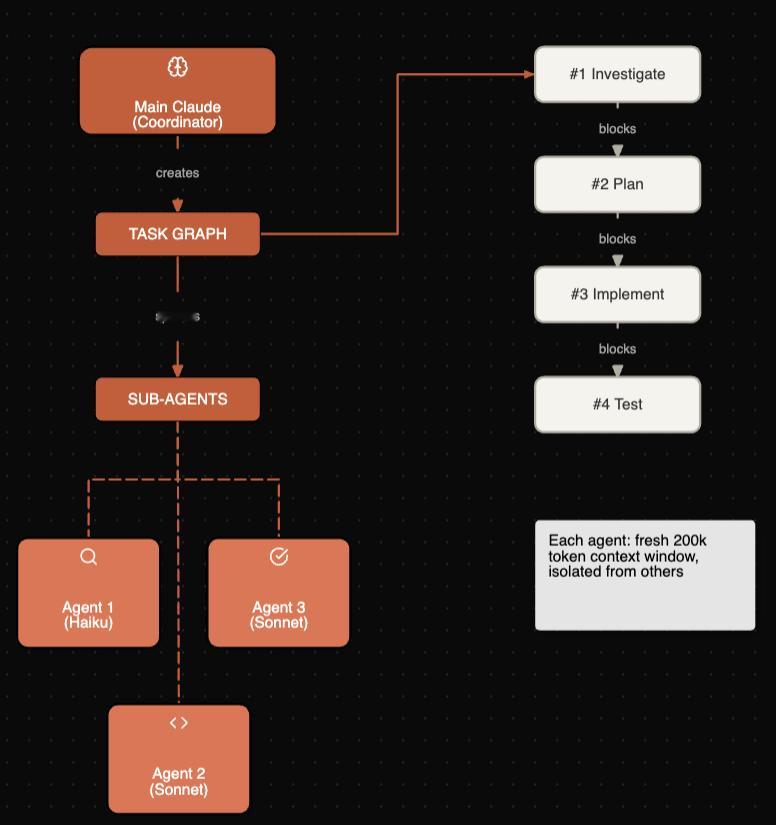
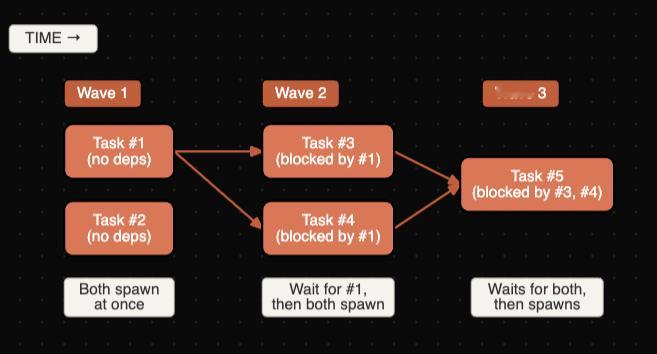
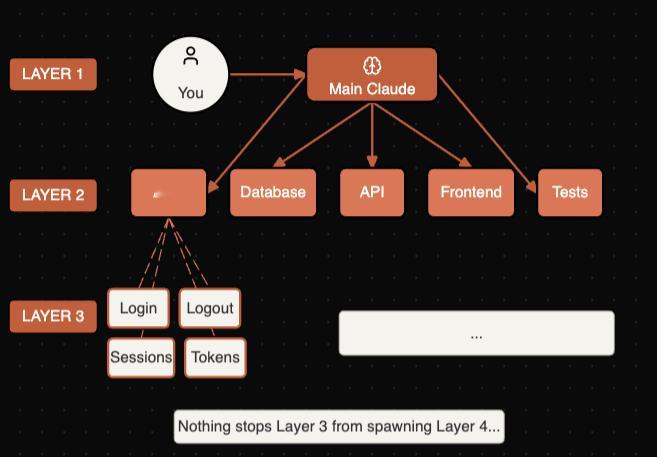
CJ Hess写了一篇介绍Claude Code 新出的任务系统(Todo替代品)的介绍。有了依赖关系管理,可以做更多复杂任务了。------------------------智能体蜂群来了我们聊“智能体蜂群”已经很多年了:多个 AI 智能体在复杂任务上协同工作,按需孵化子智能体,并行管理依赖关系。演示看起来总是很惊艳,但你真拿去做实际工作,往往就会发现一切很快散架。这周我正卡在一个大型鉴权(auth)重构中,看到 Claude Code 发布了新的任务系统。我想把它逼到极限,就做了一个超大的任务清单,让它编排子智能体把整套事情跑完……结果它居然稳稳做到了?我感觉我们刚跨过了一个很多人还没注意到的门槛。🌟大家最容易看错的点大多数人看到任务系统,会觉得“哦,就是新的待办”。确实,它表面上就是待办:现在任务能跨 /clear 保留,能跨会话重启保留;如果你设置了 CLAUDE_CODE_TASK_LIST_ID 环境变量,甚至关掉终端再开也能保留。但多数人盯错了重点。任务系统本质上是一个“协调层”。它让多个智能体并行工作,记录“谁依赖谁”,并共享一种能跨单次对话存活的状态。换个说法:以前 Claude 像一个大脑,试图把整个复杂项目同时塞进同一个脑子里;现在 Claude 可以把工作拆成多块,把每一块交给独立智能体,每个智能体有自己的上下文窗口,然后通过共享的依赖图把整体协同起来。这是完全不同的能力。🌟它到底怎么运转任务系统做的事大致是这样(图1):每个任务都可以孵化自己的子智能体,而每个子智能体都会拿到一个全新的 200k token 上下文窗口,并且与主对话完全隔离。这一点是系统能跑起来的关键。想想这种隔离带来的好处:智能体 1 在钻鉴权代码,建立“会话(session)如何处理”的完整心智模型;智能体 2 在重构数据库查询,记着 schema 的细节;智能体 3 在改测试用例,追踪哪些断言要同步调整。它们不会互相污染上下文,也不会被彼此的内容干扰,因为它们字面意义上互相看不见。这和旧方式差别巨大:旧方式下,Claude 试图在一段对话里同时记住早先的决策、实现新的改动、还要追踪哪些文件被动过。小活还能凑合,一旦复杂就会撞墙:一边写一边忘、越写越乱,最后总有东西漏掉。有了任务系统,每个智能体只盯一件事。任务完成后,被它阻塞的任务会自动解锁,下一波工作随即启动。协调能力被“写进结构里”,而不是要求 Claude 在对话里实时操心管理。🌟依赖关系才是真正的卖点这里最关键、但常被忽略的是 blockedBy。{ "subject": "Implement JWT authentication", "addBlockedBy": ["1", "2"]}这不是“建议先做什么”。任务 3 在任务 1 和 2 都完成前,系统层面根本不允许它开始。这意味着 Claude 不会因为走神、上下文拥挤、或者你 /clear 了一次,就跳过前置步骤或忘了依赖。没有依赖关系时,Claude 必须把整套计划放在工作记忆里。小计划没问题,但一复杂,随着上下文变长或被清理,你就得反复解释:目标是什么、哪些做完了、还剩什么、谁依赖谁。计划只存在于 Claude 的“脑子里”,所以非常脆弱。有了依赖关系,相当于把计划外置成一个结构:它能扛住上下文压缩,能扛住会话重启,甚至你三天后回来继续也不漂移。依赖图不会忘,也不会自己“走样”。你不需要反复解释,因为它从来就不是靠短期记忆保存的。这也是为什么 Ralph 之前靠“重新锚定”火了一阵。Anthropic 这波等于把 Ralph 的价值空间直接打穿了。🌟工作流怎么变了在任务系统之前,我的 Claude Code 使用流程通常是:1. 让 Claude 做一件很复杂的事2. 看它做到大概 60%3. 发现它在做第 5 步时把第 2 步忘了4. /clear 重来5. 重复到崩溃有了任务系统后:1. 让 Claude 先把工作拆成任务2. 你审一下依赖图3. 让它跑4. 任务只能按依赖允许的顺序完成,所以自然就按正确顺序完成结构本身在“强制正确”。依赖图存在于 Claude 的上下文之外,所以也就没东西可忘。🌟免费的并行能力有个点我花了一阵才真正意识到:你可以同时跑 7 到 10 个子智能体。想想这意味着什么:旧方式下,你给 Claude 一个 10 项任务,它通常只能串行做:1、2、3……即便其中一半互不相关,本来可以并行,它也只能在同一条对话线程里排队做。任务系统下,Claude 会看依赖图,把所有可并行的任务同时启动:任务 2、3、4 互不依赖?三个智能体就一起开工,各自拥有独立上下文、独立推进。你什么都没改变,速度就可能直接变成 3 倍。(图2)它还会为不同工作挑不同模型:快速检索用 Haiku,实现改动用 Sonnet,需要重推理时用 Opus。你不用操心资源分配或成本管理,只要定义依赖,系统就会自动编排。🌟持久化只要设置一个环境变量:export CLAUDE_CODE_TASK_LIST_ID="my-project"任务就会落在 ~/.claude/tasks/my-project/。明天开新会话还在;换个终端还是同一份任务清单;多个 Claude 会话也能看到并更新同一套任务。这对“跨多天的重构”这种工作很关键:任务图变成项目的持久状态,不依赖任何一段对话。我现在会把任务列表当成大型项目的事实来源。回来继续时,不用再把背景从头讲一遍,让 Claude 去看任务列表就能知道进度和剩余事项。结构把上下文往前带。🌟如何开始上手入门其实很简单:让 Claude 做一件复杂的事如果它自动生成任务,就让它跑如果没有,就让它“把这件事拆成带依赖关系的任务”按 Ctrl+T 打开任务视图看它执行想要持久化,把这行加进 shell 配置里:export CLAUDE_CODE_TASK_LIST_ID="your-project-name"就这些。编排、并行、依赖追踪都由系统负责。🌟接下来会走向哪里现在你还是在和 Claude 这个“主智能体”协作:你给它复杂目标,它拆解工作、建依赖图、孵化子智能体去处理各个模块。这正是我们之前设想的模式。但那些子智能体,本质上也只是拥有各自上下文窗口的 Claude 实例。它们完全可以自己也使用同一套任务系统。顺着这个想一下:你让 Claude 重构整个代码库。它先按子系统拆:鉴权、数据库、API 路由、前端、测试,孵化五个子智能体。然后鉴权智能体看自己那块仍然很复杂,于是继续细拆:登录、登出、会话、重置密码、token 刷新……它生成自己的依赖图,再孵化自己的子智能体。你就进入第三层。第三层:(图3)而且架构上没有硬性天花板:限制来自上下文与成本管理,而不是能力本身。现在我们大概在第二层,但往更深走的脚手架已经搭好了。我一直在想这对软件开发意味着什么。几十年来,核心技能是写代码;后来变成设计系统;再后来变成编排团队。每一次上移都是更高抽象层的思考,但底层总有“有人在写具体代码”。这个底层正在变化。再过几年,也许更快,关键技能可能不再是写代码,甚至不再是架构设计,而是把问题定义得足够清晰,让智能体蜂群能把它解出来。你的工作变成:知道要做什么、为什么重要、成功标准是什么。实现层面的重构、测试、调试、跨服务协调,会被层层智能体接管。这不是“AI 取代开发者”。那种表述没抓住重点:角色只是再往上抽象了一层,就像每隔十年发生一次那样。你变成一个协调层级的顶部,而这个层级的执行规模,在不久前可能需要 20 个人才能做到。还有个让我睡不着的点:谁先把这套东西用顺了,谁就会获得难以夸张的杠杆。现在做一个野心大的东西,你通常需要资金、团队、几个月时间。很快你可能只需要一张信用卡,以及把你要做的东西描述清楚到足以让智能体执行。软件构建门槛正在坍塌——不是那种“人人都会写代码”的老说法(那一直有点自欺欺人,因为大多数人根本不想写代码),而是对那些知道自己想做什么、但不想花半年亲手敲出来的人,门槛在快速下降。那会是一个完全不同的世界。我不确定具体会怎么展开。可我愿意赌:三年后会有人在一个下午上线一个生产级应用,而今天这可能需要一个团队做六个月。也许我没看到某些瓶颈,但方向很清楚。我们聊智能体蜂群很多年了。这是我第一次看到这种架构在真实工作里确实跑通。任务系统看起来像待办清单,但底层跑的是“分层多智能体系统”的协调层。清单只是 UI。你不再是在管理任务。你是在指挥一群蜂群。而我们现在还只是第二层。HOW I AI科技先锋官