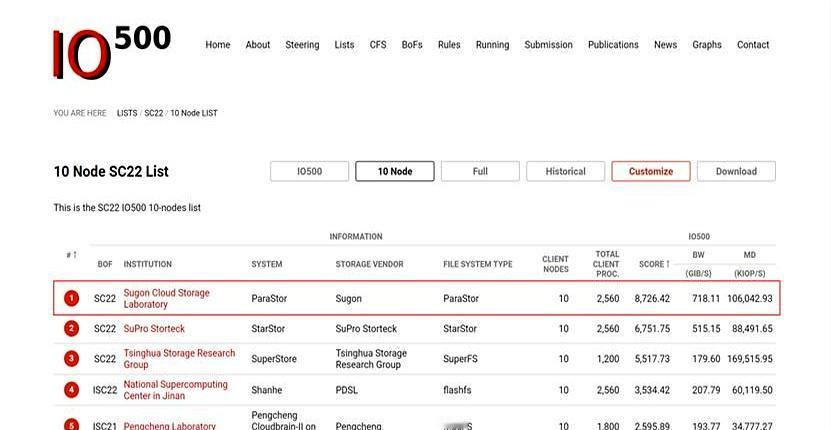
刚参加完一场智算行业交流会,发现政企朋友们都提到一个趋势:未来,十万卡级的算力集群将成为标配,而当下万卡集群已经卷起来了。 可是很多人把设备买回去才发现不对劲。 几亿砸下去买了最顶级的GPU,结果模型训练起来还是慢吞吞,甚至经常卡顿。 这就像买了辆法拉利,却只能在泥巴路上开,发动机再好也跑不起来。 其实,真正的瓶颈早就变了,现在卡脖子的不是算力,而是怎么把海量的数据快速“喂”给这些显卡。 这就是为什么曙光存储的那个“超级隧道”技术最近这么火。 它解决了一个最根本的痛点:修路。 以前数据从存储跑到GPU,中间要经过好几道手续,还要排队,这一来二去速度就慢了。 曙光直接给数据修了一条直达专线,不做多余的拷贝,中间也不停车,一路绿灯直奔显卡。 这效果有多夸张? 原本要跑几个月的万亿参数模型,现在训练周期直接缩短了60%以上,速度提升了整整4倍。 对于企业来说,这省下来的时间全是真金白银。 而且,现在的存储系统已经不是简单的“仓库”了,它更像是一个智能的“加工厂”。 曙光搞的这个“AI数据工厂”,能让存储设备自己动脑子。 GPU还没张嘴要呢,存储侧就已经把数据预处理好了,甚至能帮着分担一部分计算任务。 这配合度,简直就是顶级大厨配上了最懂事的帮厨,炒菜效率能不高吗? 看看这背后的硬家伙,ParaStor F9000刷新了IO500的纪录,单节点带宽干到了220GB/s,这就是底气。 以后的AI竞争,光靠堆显卡数量已经行不通了,谁能让数据流转得更快,谁能把存力转化为生产力,谁才是真正的赢家。 这场看不见的效率革命,其实比单纯拼硬件参数要精彩得多。