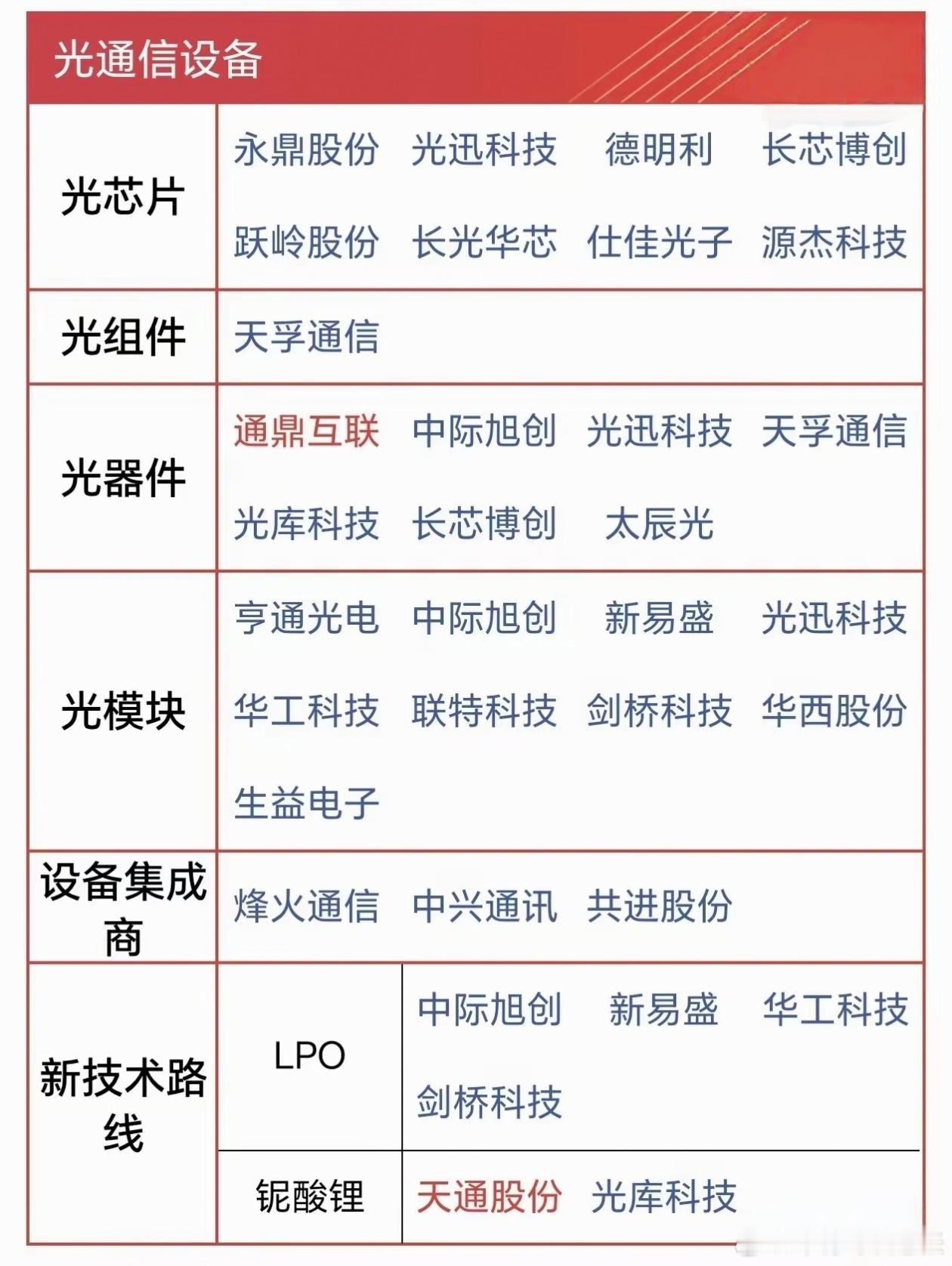
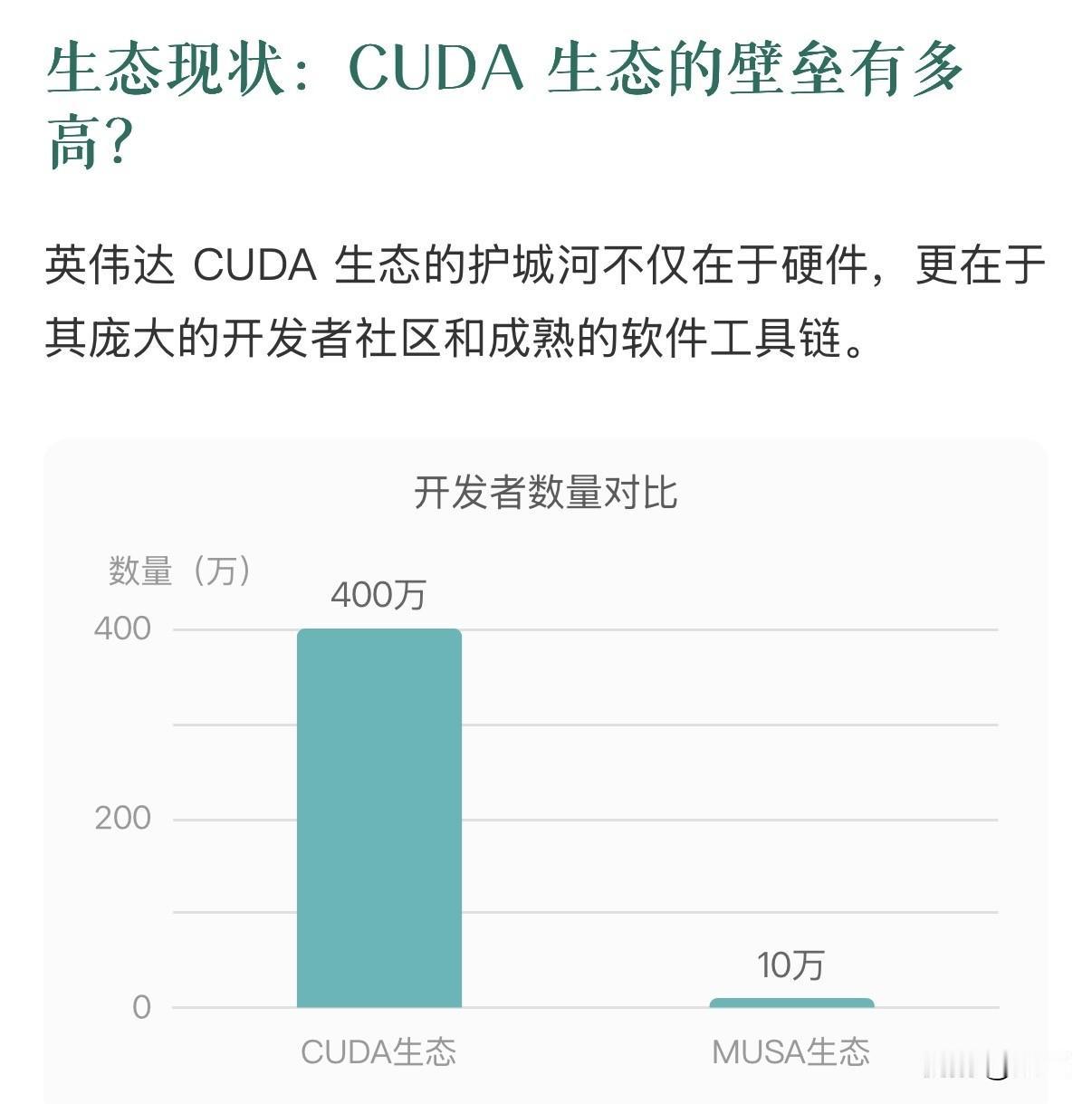
2025年12月20–21 日,摩尔线程在北京中关村国际创新中心举办首届 MUSA 开发者大会,一口气发布: “花港”新架构、 “华山”AI 芯片、 “庐山”图形芯片、 “夸娥”万卡集群与 AI 算力本, 宣告国产 GPU 正式迈入“万卡智算”时代。 1. “花港”全功能 GPU 架构 全精度覆盖:原生支持 FP4→FP64,新增 MTFP6/MTFP4 混合低精度。 性能能效:算力密度 +50%,能效最高提升 10 倍。 集群规模:单集群可扩展至 10 万卡以上。 图形升级:第二代硬件光追 + AI 生成式渲染(AGR),光追性能跃升 50×。 安全设计:四级硬件安全体系,支持国密算法与机密计算。 2. “华山”AI 训推一体芯片 基于花港架构的旗舰 AI 芯片,定位超智融合场景。关键指标: 浮点算力对标英伟达 Hopper,部分指标媲美 Blackwell, 单卡支持 1024 GPU 直连 Scale-Up,内置 RAS 2.0 可靠性机制, 兼容 MTLink 4.0 + 以太协议,面向十万卡 AI Factory。 3. “庐山”高性能图形芯片 面向 CAD/CAE、数字孪生、3A 游戏等场景: 图形性能提升 15×,AI 算力提升 64×,光追提升 50×, 显存容量 4× 于上一代,完整支持 DirectX 12 Ultimate, 内置 AI 生成式渲染(AGR)与统一任务引擎,渲染管线全面并行。 4. “夸娥”万卡智算集群 浮点算力 10 Exa-FLOPS,Dense 模型 MFU 60%,MoE 模型 MFU 40%, 有效训练时间占比 ≥90%,线性扩展效率 ≥95%, 原生 FP8 训练,Flash Attention 算力利用率 95%, 配套 MTT C256 超节点:8 交换节点 + 216 计算节点,180 kW 功耗设计,面向下一代十万卡集群。 开发者生态与工具链: 摩尔线程同步推出 MUSA 5.0 全栈软件,覆盖驱动、编译器、算子库、调试与性能分析工具,兼容 CUDA/OpenCL/Vulkan/DirectX 12 Ultimate,降低迁移成本。 同时发布: MTT AIBOOK:搭载 50 TOPS “长江” SoC 的 AI 算力本,打通 Linux 开发 / Windows 办公 / Android 应用三端场景。 摩尔学院:面向 20 万开发者提供课程、认证与社区支持。 摩尔线程 摩尔线程市值 摩尔年终大促 英特尔芯片项目 首届 MUSA 开发者大会