Agent Leaderboard v2:企业级AI Agent评测新标杆
• 真实多行业场景覆盖:涵盖银行、医疗、投资、电信、保险五大关键领域,模拟5-8个多轮交互、多目标复杂对话,考验AI代理跨上下文协同与动态决策能力。🔍
• 核心评测指标:
– Action Completion(动作完成率)衡量代理是否完整、准确地完成所有用户请求,反映实际问题解决能力;
– Tool Selection Quality(工具选择质量)考察代理是否正确且精确调用合适工具,避免冗余或错误调用。
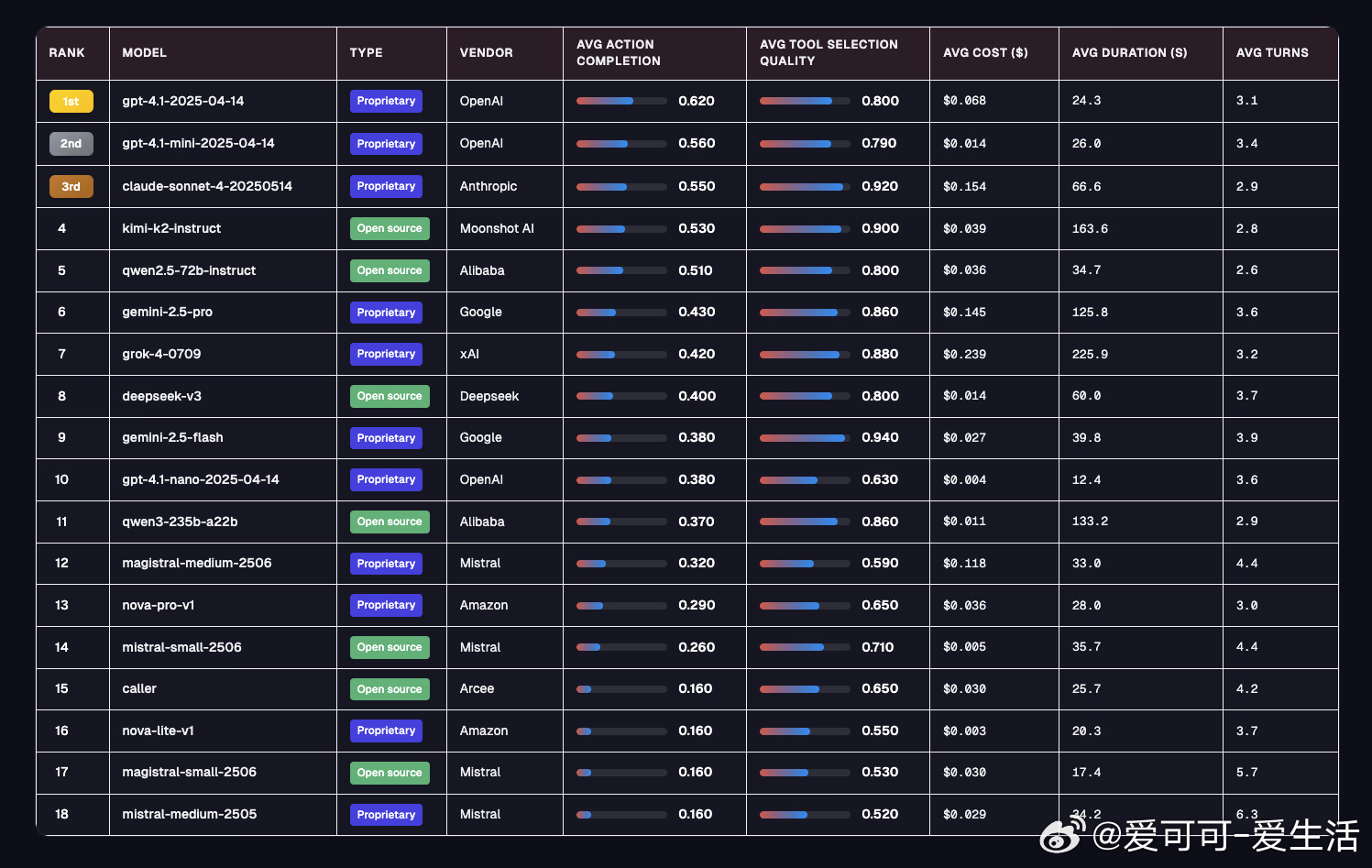
• 领先模型表现:GPT-4.1平均动作完成率62%领跑全局,Gemini-2.5-flash工具调用精度高达94%,但任务完成仅38%;开源新秀Kimi K2表现优异,性价比高。
• GPT-4.1 引领整体表现,综合能力突出
• Gemini-2.5-flash 在工具选择上表现卓越,擅长多任务协作
• Kimi K2 荣膺最佳开源模型,开源社区活力强劲
• Grok 4 表现不足,尚需优化提升
• 推理能力模型普遍滞后,仍是技术瓶颈
• 目前无单一模型能全面统治所有应用领域,选择需根据场景精准匹配
• 数据集与模拟引擎:采用合成数据构建行业专属工具、用户画像与复杂场景,保证无数据泄露且测试环境公平、可控。
• 评测意义:突破传统静态单步测试,真实还原企业客户服务复杂性,助力企业精准选型,规避单一模型“泛化”误判。
• 持续迭代:月度更新模型库,未来支持多代理协作评测,按需扩展行业覆盖,紧跟AI代理技术发展节奏。
Agent Leaderboard v2为企业打造贴合实际需求的AI代理综合考核体系,推动AI服务质量与可靠性迈向新高度。
介绍🔗 galileo.ai/blog/agent-leaderboard-v2
详细了解🔗 galileo.ai/agent-leaderboard
代码仓库🔗 github.com/galileo-ai/agent-leaderboard
人工智能企业AI多轮对话AI评测智能客服开源AI