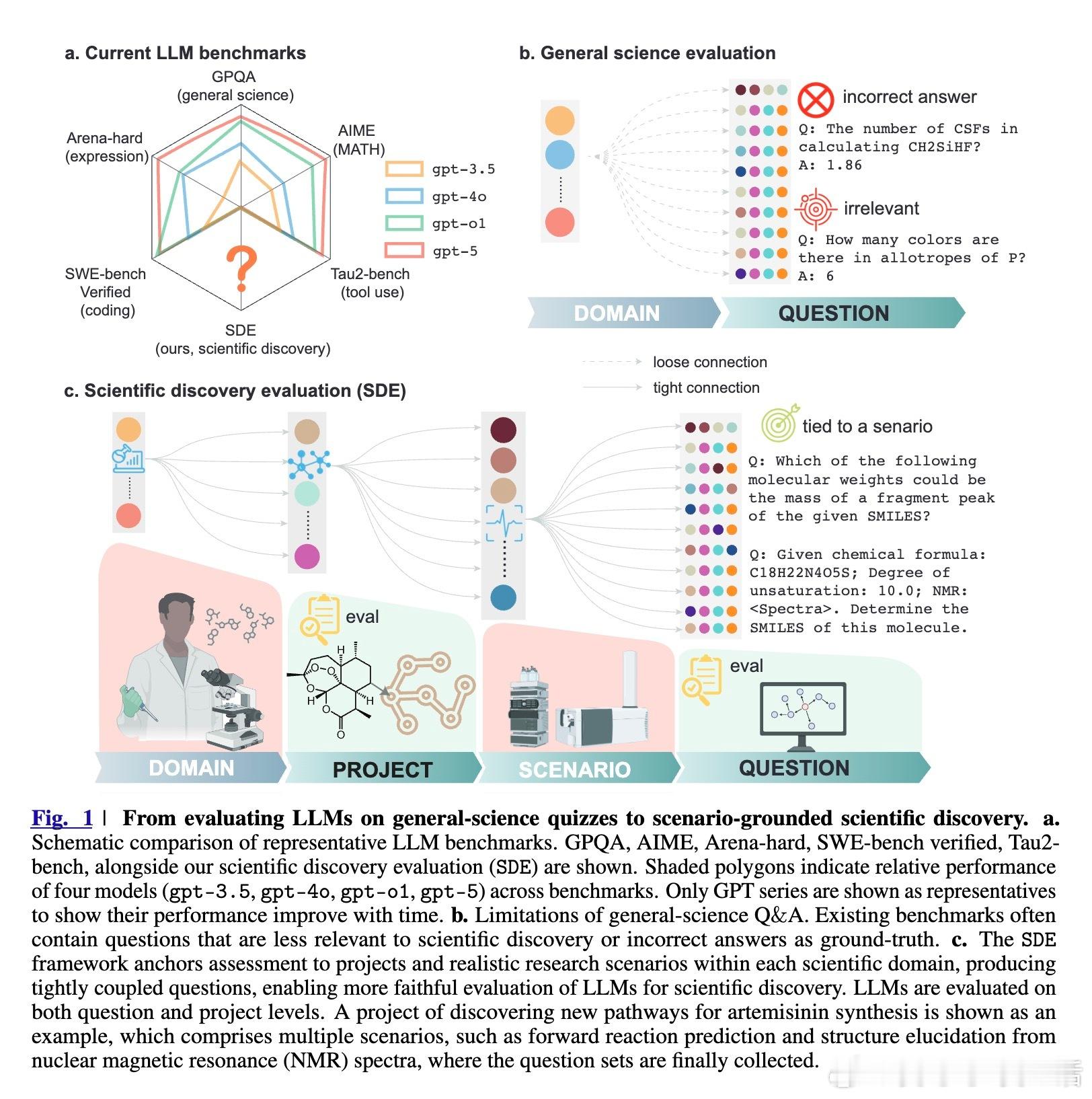
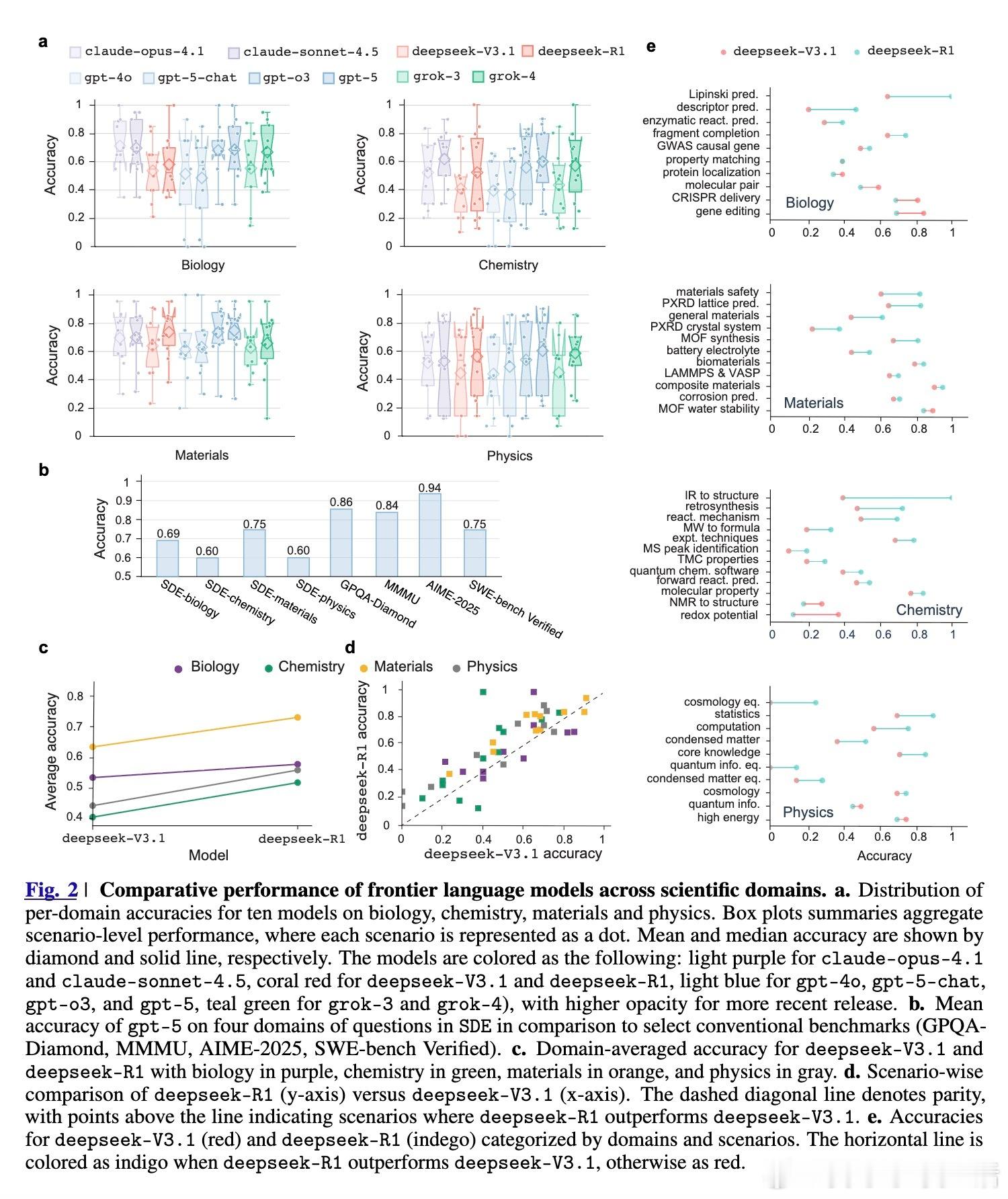
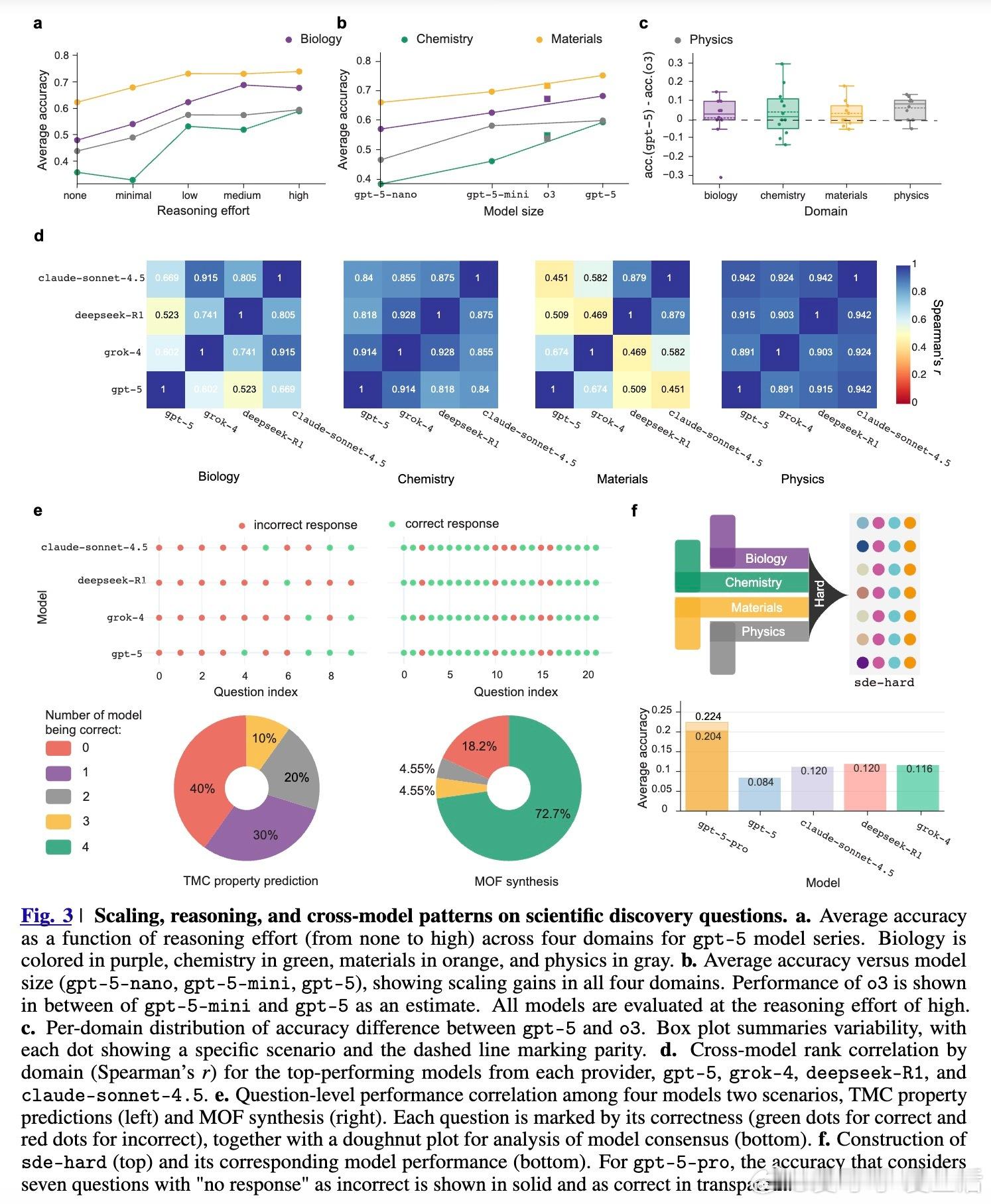
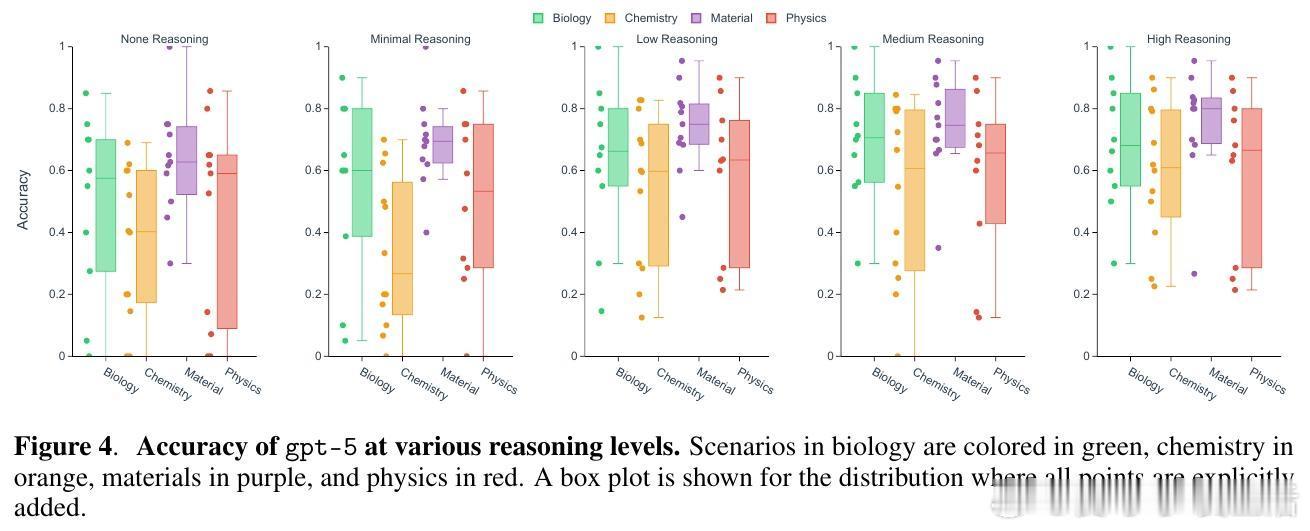
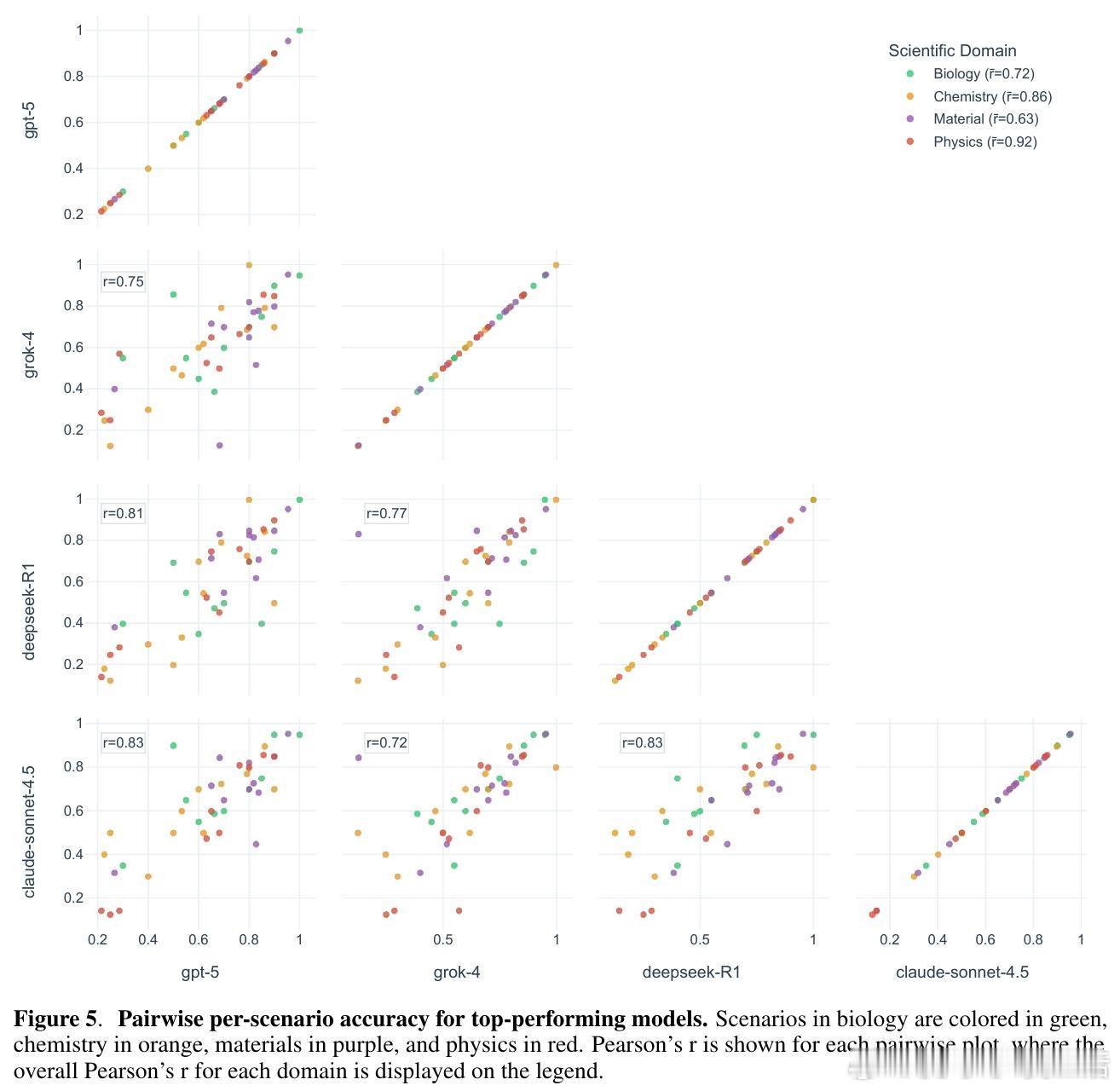
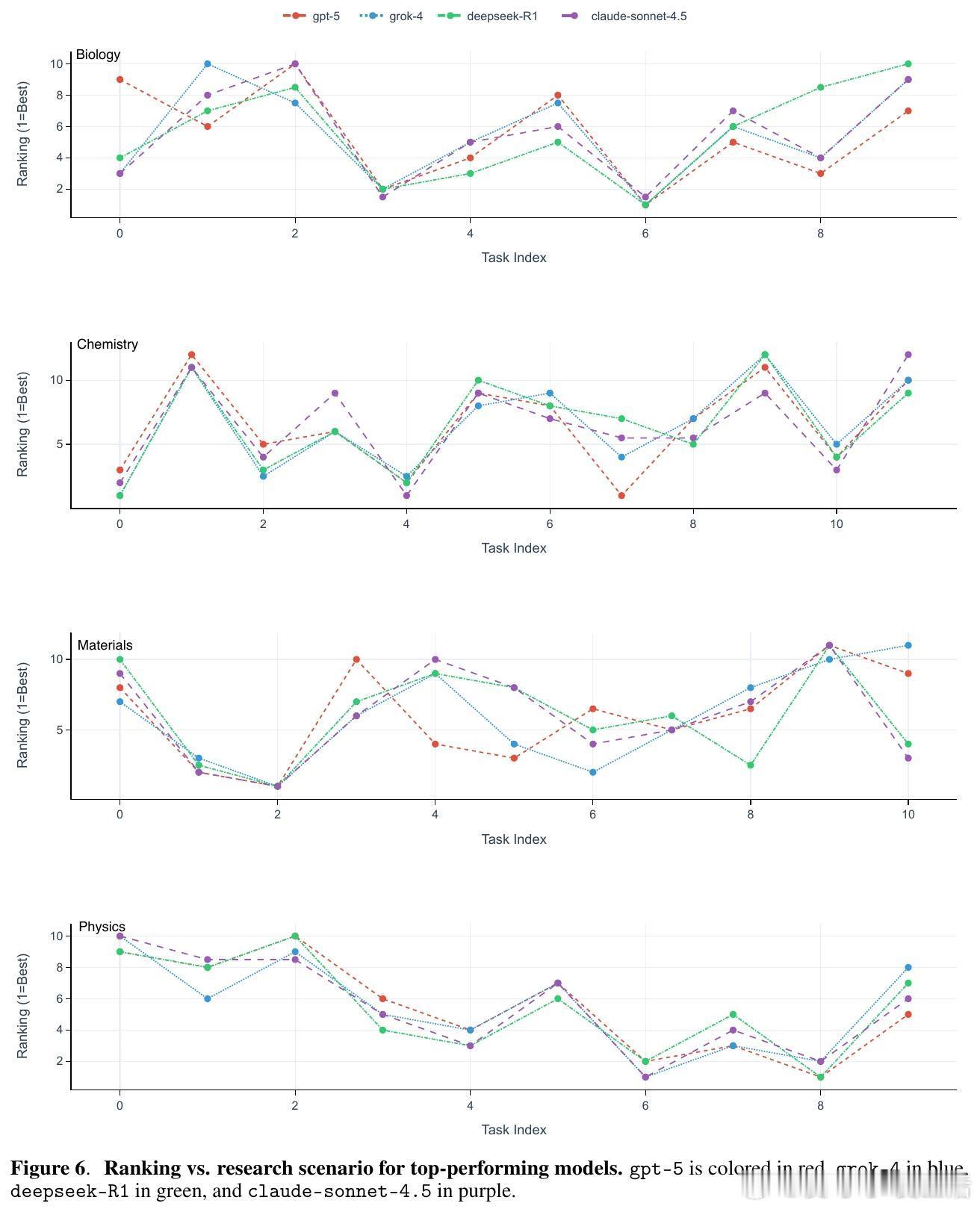
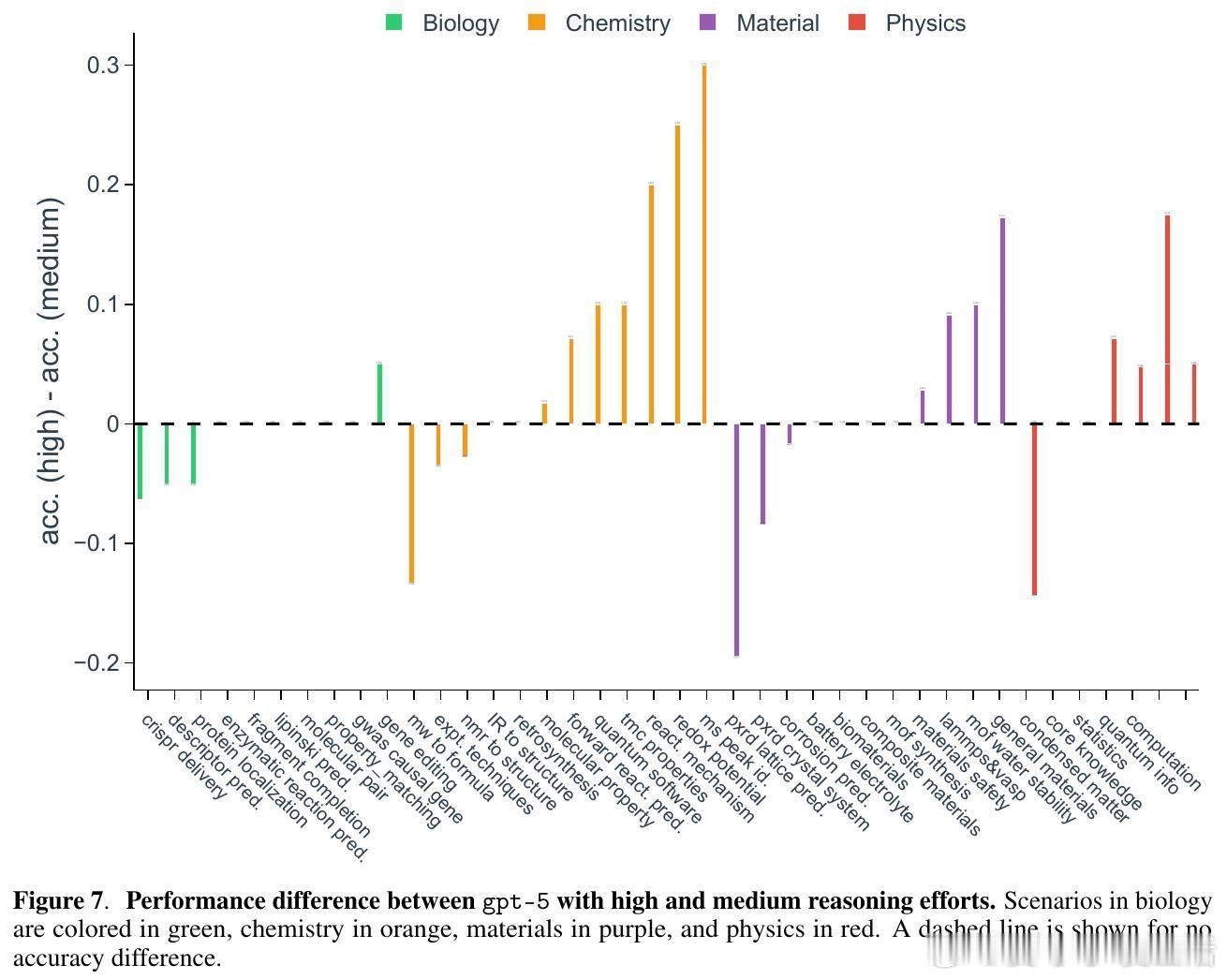
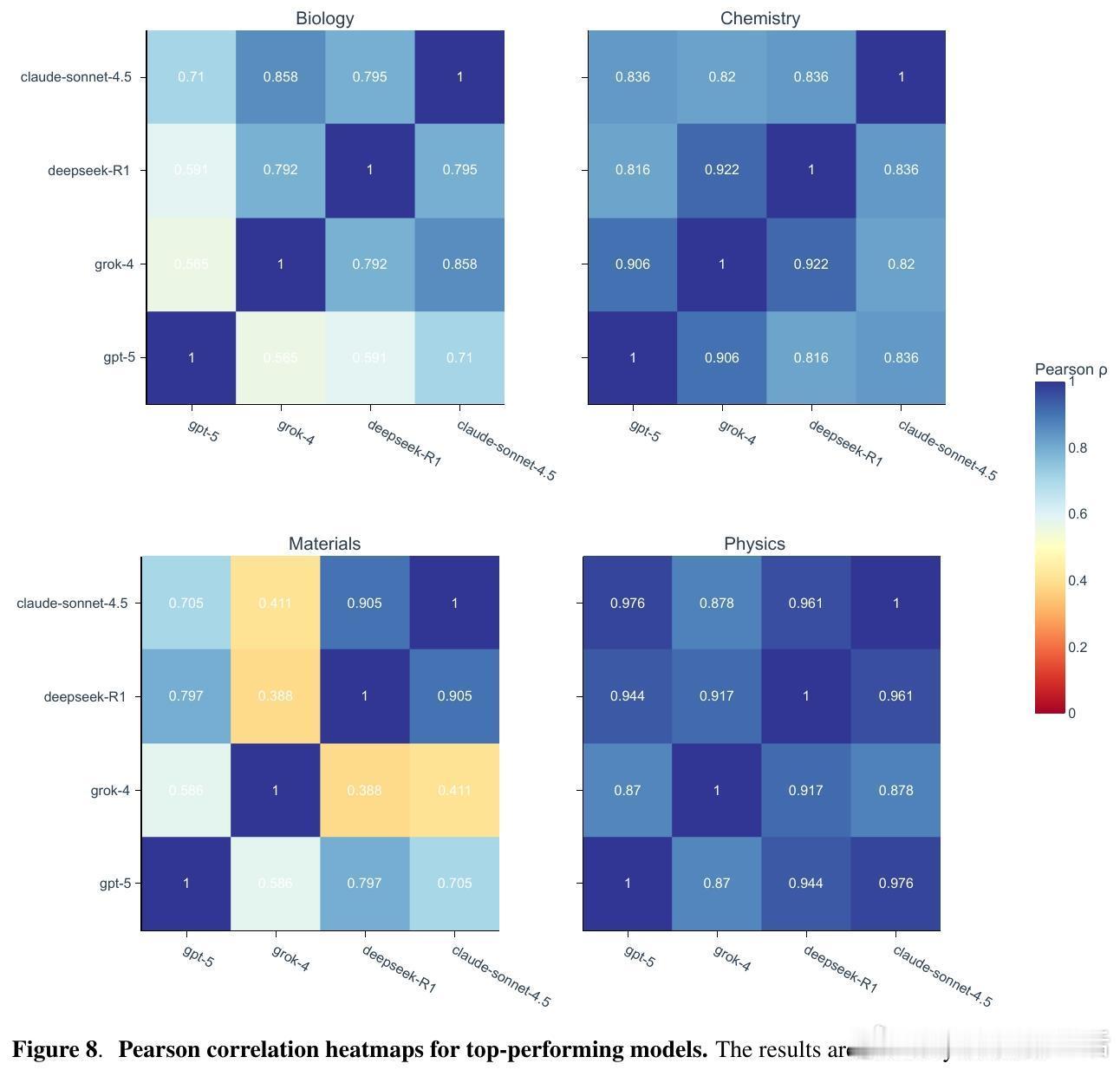
[AI]《Evaluating Large Language Models in Scientific Discovery》Z Song, J Lu, Y Du, B Yu... [Deep Principle & Cornell University & The Ohio State University] (2025) 本文为我们揭示了大语言模型(LLM)在科学发现领域的真实边界。它不仅是一个榜单,更是一次关于AI能否真正“做科研”的深度审视。考试拿高分不代表能做科研,LLM也面临同样的困境。目前的科学基准测试(如GPQA)大多是脱离语境的问答,模型表现优异往往是因为记住了知识点。但这与真实的科研过程相去甚远。科研不是在选择题中寻找标准答案,而是在充满噪声的实验中提出假设、设计方案并解读结果。为了弥补这一鸿沟,研究团队推出了SDE(Scientific Discovery Evaluation)框架。SDE框架将评价分为两个维度:一是基于真实科研场景的知识问答,二是闭环的科学发现项目。涵盖生物、化学、材料、物理四大领域,由领域专家将复杂的科研项目拆解为模块化的场景。这种设计让评估从“背诵课本”转向了“实战演练”。评估结果揭示了一个残酷的现实:即便是在通用科学测试中接近满分的模型,在面对真实的科研场景时也会出现明显的性能滑坡。首先,规模效应和推理能力的提升正在进入平台期。研究发现,随着模型尺寸的增加和推理步数的延长,其在科学发现任务上的回报率正在递减。这意味着,单纯依靠增加算力或延长思考时间,可能无法跨越从“知识问答”到“科学发现”的最后一道门槛。其次,顶尖模型之间存在系统性的“共同弱点”。无论是GPT-5、Claude还是DeepSeek-R1,它们往往在同一批难题上集体折戟。这种错误的高度一致性暗示,现有的模型架构和训练数据分布可能存在某种共同的局限。当所有顶尖模型都在同一个问题上犯错时,说明我们触碰到了现有范式的天花板。有趣的是,模型在具体知识点上的得分,并不总是能预示其在科研项目中的表现。在某些复杂的化学优化项目中,即便模型对底层物理属性的预测并不完美,它们依然能通过敏锐的探索直觉找到最优解。这说明科学发现需要的不仅是完美的记忆,更是对不确定性的驾驭和某种程度上的“意外发现”能力。然而,在需要严密逻辑链条的任务中,如多步逆合成分析,目前的LLM依然表现挣扎。它们经常在长程规划中迷失,或是在基础的有效性检查中犯错。目前还没有任何一个模型能称霸所有的科研项目,所谓的“科学通用超智能”依然遥不可及。SDE框架为未来的AI科研助手指明了方向:我们不应只追求更大的模型,而应关注如何让模型理解科研语境、熟练调用专业工具,并在强化学习中注入科学逻辑。科学发现的本质是向未知的边界探索,而不仅仅是在已知的语料库中回溯。LLM已经展现出了成为科研“副驾驶”的巨大潜力,但要成为独立的“科学家”,它们还需要学习如何在没有标准答案的迷雾中行走。原文链接:arxiv.org/abs/2512.15567