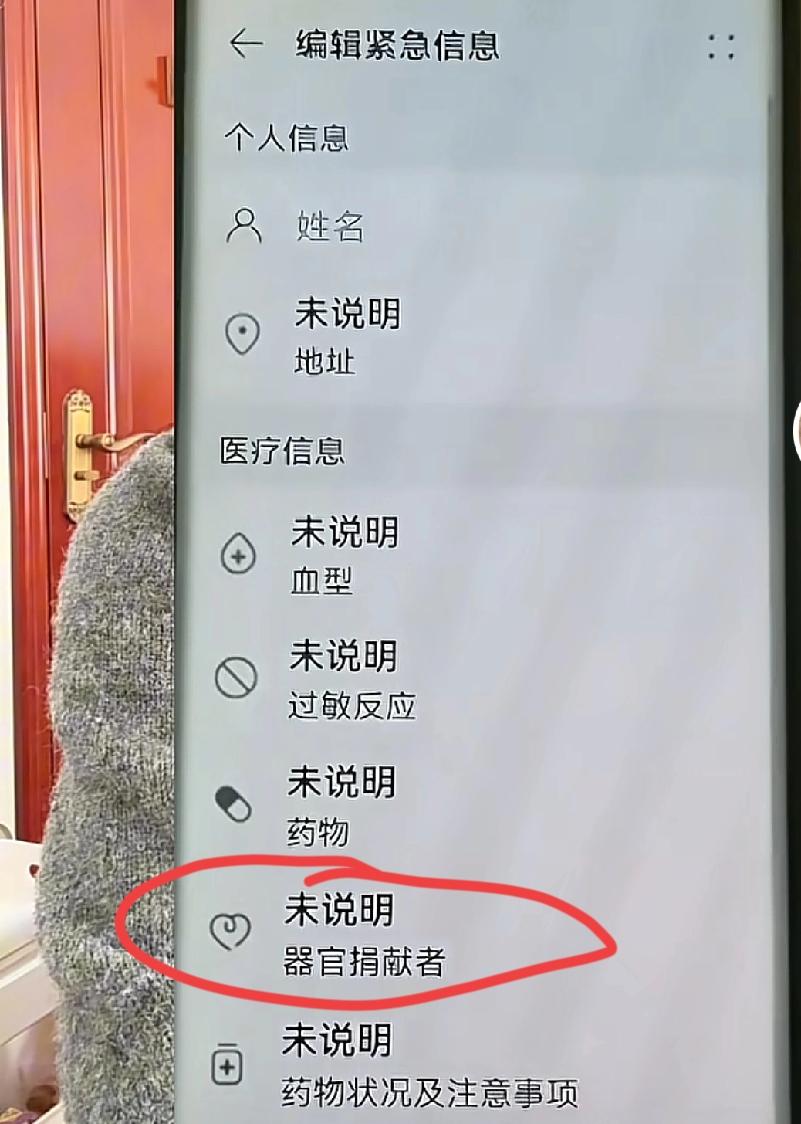
记者问:“中美 AI 差距到底有多大?” 梁文锋毫不避讳、一针见血地回答:“表面上中国 AI 与美国可能仅有一两年的技术代差,但真实的差距是原创和模仿之差。如果这个差距不改变,中国永远只能是追随者,所以有些探索是逃不掉的。” 大家可能对梁文锋不算陌生。他是量化私募幻方量化的创始人。他还是国产大模型企业DeepSeek的创始人。他在AI领域摸爬滚打多年,既有技术研发经验,又有产业落地经历。他的话没有半点虚的,也说出了很多人不愿正视的现实。 咱们在AI领域跑得确实不算慢。短视频里的AI特效。购物时的智能推荐。还有医院里的AI辅助诊断。这些应用场景咱们覆盖得又广又快。市场上的AI产品更新速度也很快。不少产品用起来的体验,跟国外同类产品差别不大。 但很多时候咱们还是跟着别人的脚印走。别人先做出了大语言模型。咱们就跟着研发类似的模型。别人推出了AI绘图工具。咱们就跟着优化相关功能。这种模仿能让咱们快速跟上潮流。这种模仿却没法让咱们真正引领潮流。 表面的技术代差很好追赶。一两年的时间足够咱们的企业做出类似产品。原创能力的差距才是最致命的。原创能力决定了谁能制定行业规则。原创能力决定了谁能掌握核心技术主动权。 其一咱们先看基础层的情况。AI发展离不开算力支撑。算力就相当于AI的“发动机”。美国在算力领域占据绝对优势。全球70%以上的新增智能算力都集中在美国。微软、OpenAI等巨头还在持续加码投入。他们计划2025年的相关算力投入超千万级GPU。 咱们中国的智能算力规模不足美国十分之一。咱们还受芯片限制。高性能芯片大多依赖国外进口。国产芯片在性能和生态构建上还有不小差距。即便咱们的企业想加大研发投入。也会面临算力不足的困境。 数据是AI发展的另一个核心。美国拥有超百年积累的海量多元数据。这些数据涵盖多个领域。他们还把控着互联网核心枢纽。这就确保了数据的稳定充足供应。咱们的AI训练数据多以中文为主。产业界的数据积累有限。乐观估计也不足美国十分之一。 其二技术层的差距更明显。全球主流的深度学习框架。比如TensorFlow、PyTorch。这些都由美国企业或研究机构主导。它们构建了完善的开发者社区和工具链。成为了事实上的行业标准。 咱们的国产框架虽然取得了一定进展。但在全球开发者中的普及率很低。开源活跃度和第三方支持也不足。难以形成独立的技术生态。没有自主的算法框架。咱们的AI发展就容易受制于人。 大模型领域的情况也类似。所有原始创新和核心技术突破。基本都源自美国。咱们的大模型大多处于模仿阶段。虽然在推理模型和垂直行业大模型数量上领先。但综合智力表现差距很大。 咱们的AI专利申请量远超美国。这是一个很亮眼的成绩。但其中绝大多数是实用新型专利。发明专利仅占申请总量的23%。这反映出咱们的创新能力集中在低门槛、短周期的技术改进上。缺乏对底层核心技术的原创性突破。 美国同期有85.6%的专利仍在持续支付维护费用。这显示出他们的企业对技术资产的高度重视和长期布局能力。咱们95%的人工智能设计专利和61%的实用新型专利将在五年内失效。这种差距值得咱们警惕。 其三人才和产业链协同也有不足。人工智能是高度交叉的产业。需要产学研用深度融合。咱们当前各主体之间的协作机制不健全。高校和科研机构的研究成果难以有效转化为企业可用的技术产品。企业间也缺乏开放合作的生态氛围。 美国汇聚了全球50%以上的顶尖AI人才。他们的“耐心资本”与高校、企业的协同机制更为成熟。咱们虽然培养了全球47%的顶级AI研究人员。但整体创新活力得分远低于美国。具备复合背景的高端AI人才极为稀缺。尤其在基础理论、芯片设计等领域。 很多人可能会觉得。咱们在应用层面已经很厉害了。没必要纠结原创的问题。这种想法其实很片面。没有原创的核心技术。应用层面做得再花哨也只是“空中楼阁”。别人随时可能在核心技术上“卡脖子”。 梁文锋的团队一直在做原创探索。他们发布的DeepSeek系列模型。在数学、代码等任务上性能比肩国外顶尖模型。他们还开源了模型权重和训练技术。希望促进整个行业的原创交流。 咱们不是没有突破的可能。国产算力和数据生态正加速成熟。2024年推理芯片国产化率已达42%。国产框架的影响力也在逐步提升。越来越多的企业开始加大基础研究投入。 正视差距不是自我否定。正视差距是为了更好地突破。咱们在AI领域确实跑得很快。但只有从模仿转向原创。才能真正走出自己的路。才能从追随者变成引领者。 这条原创之路可能会很艰难。这条路上充满了未知和挑战。但正如梁文锋所说。有些探索是逃不掉的。相信随着更多人投身原创研究。咱们的AI产业一定能实现真正的自主可控。