[LG]《Preference Learning with Response Time: Robust Losses and Guarantees》A Sawarni, S Sarmasarkar, V Syrgkanis [Stanford University] (2025)
本文提出了一种创新的偏好学习框架,结合了用户决策的响应时间信息,以提升奖励模型的学习效率与鲁棒性。传统的偏好学习仅利用二元选择数据,虽广泛应用于推荐系统、机器人教学、大型语言模型微调等领域,但忽略了决策时间这一隐含的强偏好信号。心理学与认知科学表明,响应时间与偏好强度呈显著的负相关,快速决策往往对应明确偏好,缓慢决策则暗示难以区分的选项。
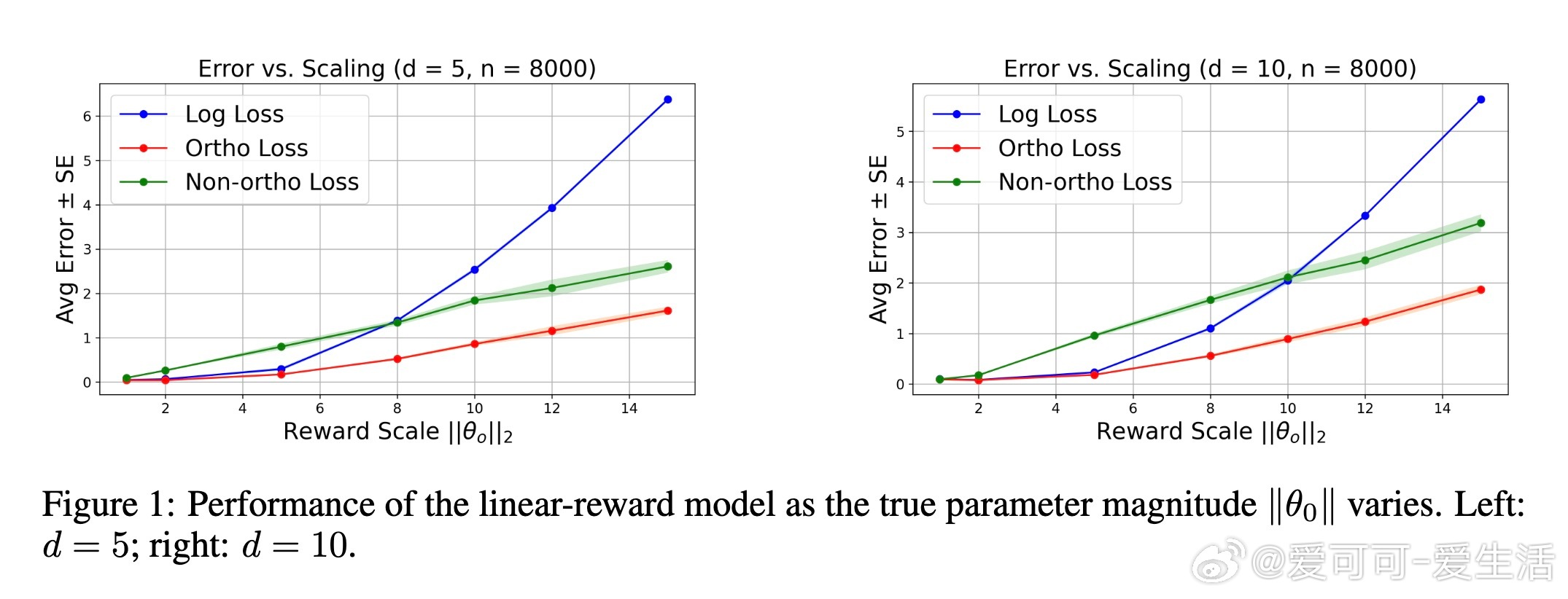
本文基于认知心理学中的Evidence Accumulation Drift Diffusion(EZ扩散)模型,设计了一个Neyman-正交的损失函数,将响应时间与二元偏好数据联合建模。该损失函数保证了对响应时间估计误差的鲁棒性,实现了与已知响应时间的理想oracle模型同阶的收敛速度。理论分析表明:对于线性奖励函数,传统基于偏好的学习误差会随着奖励幅度呈指数增长,而响应时间增强的正交估计器将误差控制在多项式规模,极大提升了样本利用率。此外,本文推广了该方法至非参数奖励函数空间(包括RKHS和神经网络),并证明了有限样本的收敛保证。
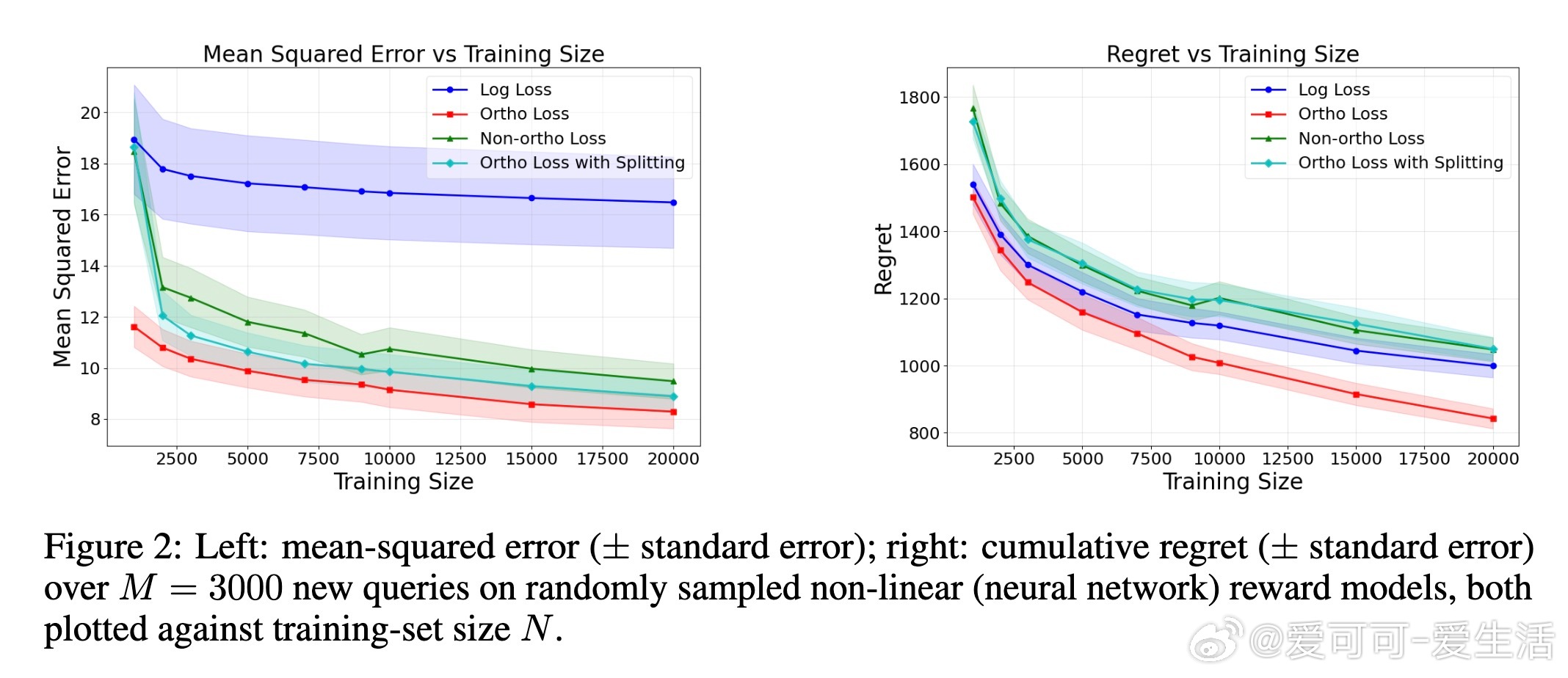
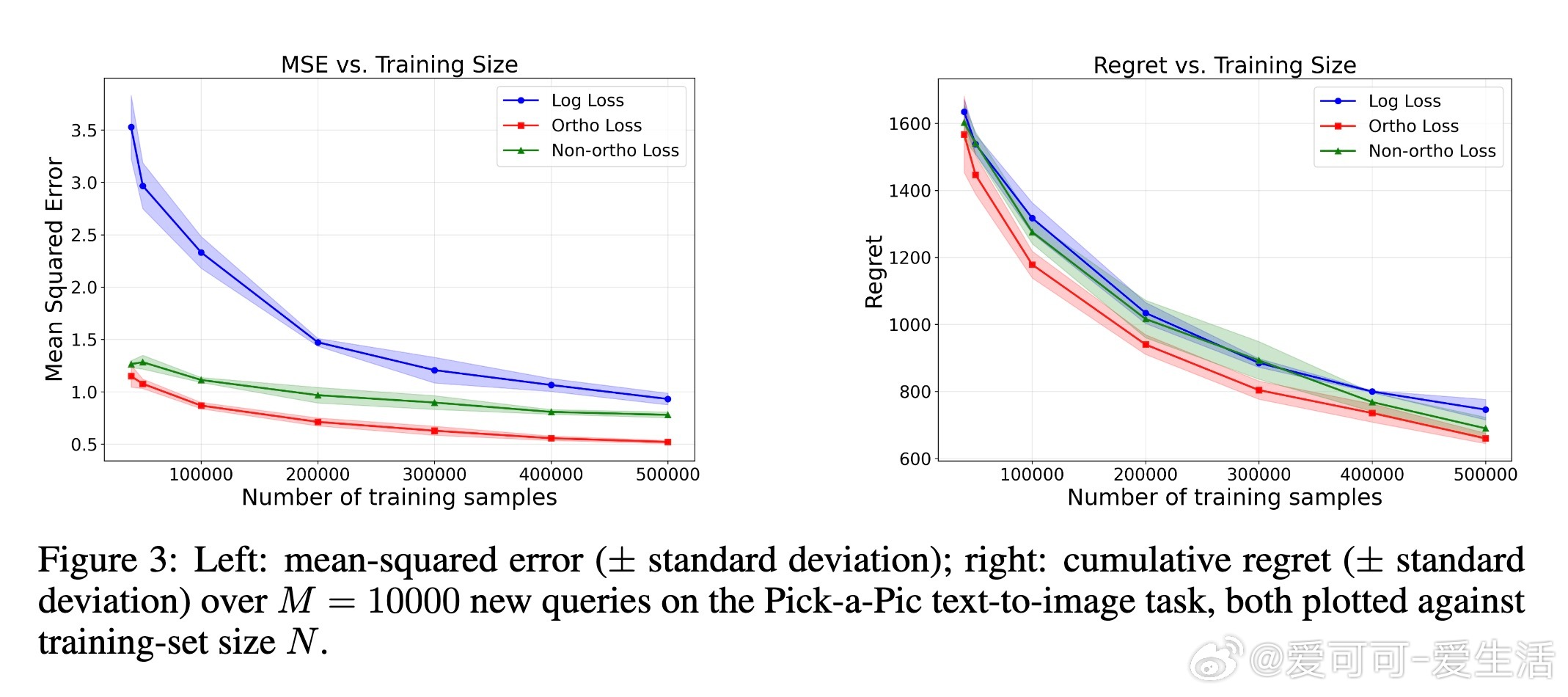
实验部分涵盖了线性奖励模型、非线性神经网络模型以及真实文本到图像偏好数据集(Pick-a-pic)上的半合成实验。结果显示,正交损失函数在均方误差和策略后悔率上均显著优于仅用偏好信息的传统对数损失和非正交响应时间损失。此外,将该方法嵌入主动查询的最优臂识别算法中也获得了更优性能。
核心贡献总结:
1. 创新提出基于Neyman正交理论的联合响应时间与偏好数据损失函数,理论与实践均优于传统方法。
2. 证明在被动采样与未知奖励分布下,正交估计器在奖励幅度增大时表现出指数级的误差改善。
3. 推广至复杂非线性奖励模型,给出了有限样本误差界与收敛率。
4. 在多种合成及半合成数据集上验证了方法的有效性,支持高维复杂输入如文本与视觉特征。
未来展望包括:拓展到在线对决带臂设置以实现更高效的在线学习;在真实响应时间数据上的鲁棒性验证;以及将正交损失应用于直接策略优化(如DPO方法),进一步提升从人类反馈学习的效率和准确性。
论文代码已开源,便于复现和推广:
论文链接:arxiv.org/abs/2505.22820v2
总结而言,本研究通过巧妙融合认知科学模型和统计机器学习理论,显著提升了偏好学习中从响应时间隐含信号中提取信息的能力,推动了人类反馈驱动的奖励建模向更高效、更鲁棒方向发展,具有广泛的应用潜力和创新价值。