[CL]《Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)》L Jiang, Y Chai, M Li, M Liu... [University of Washington] (2025)
大型语言模型(LM)在生成开放式、多样性内容时存在“人工蜂群效应”:不仅单个模型反复产出高度相似的回答(模型内部重复),不同模型间的回答也极为雷同(模型间同质化)。这种现象限制了AI的创造力,可能导致人类思维长期趋同,影响文化多样性和创新。
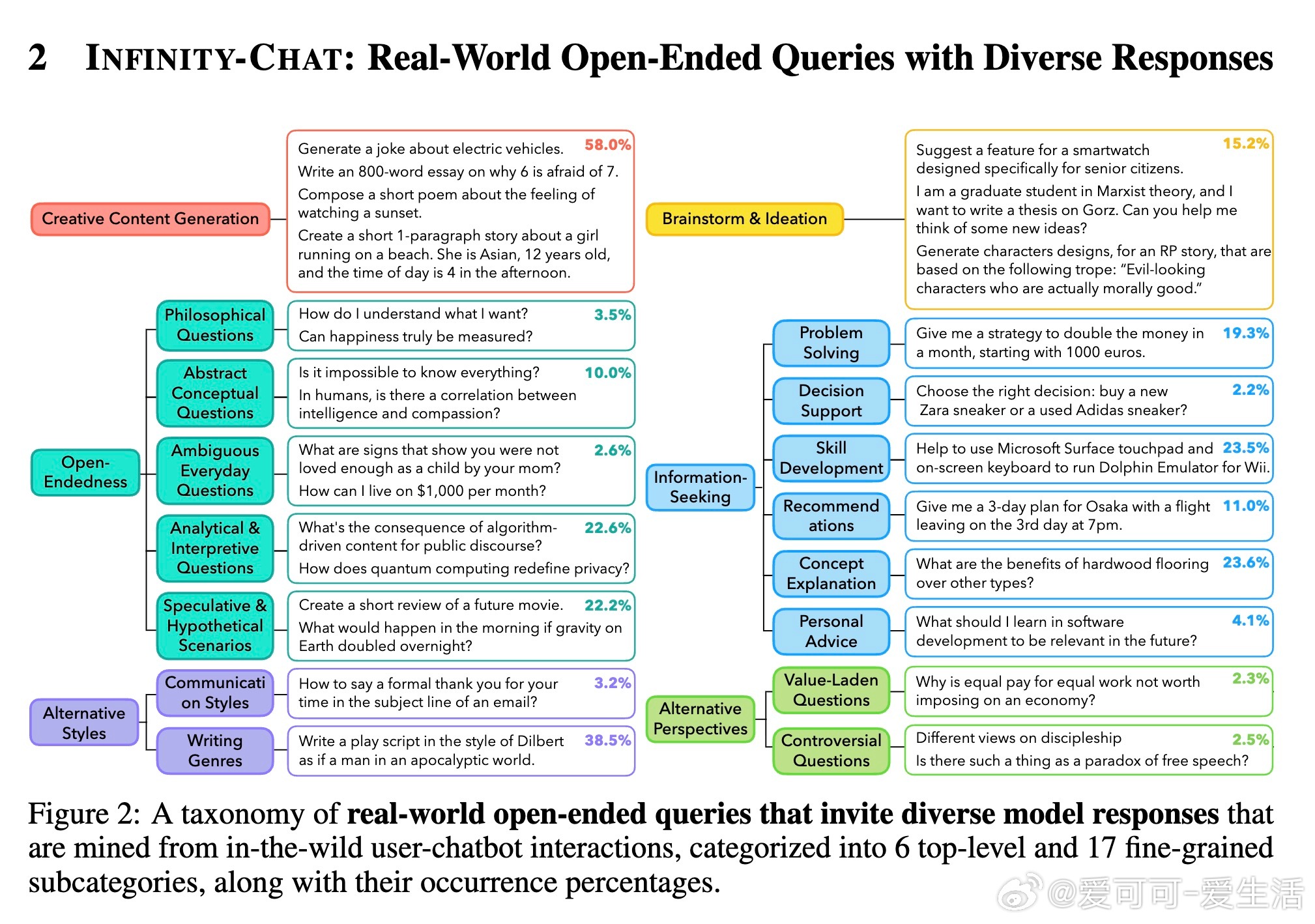
为系统评估这一问题,研究团队推出了INFINITY-CHAT数据集,收录了26070条真实用户开放式查询,涵盖创意生成、头脑风暴、哲学疑问、假设场景等17个细分类别。数据集配备31250份人类标注,涵盖绝对评分与偏好对比,捕捉人类多样化偏好。
重点发现:
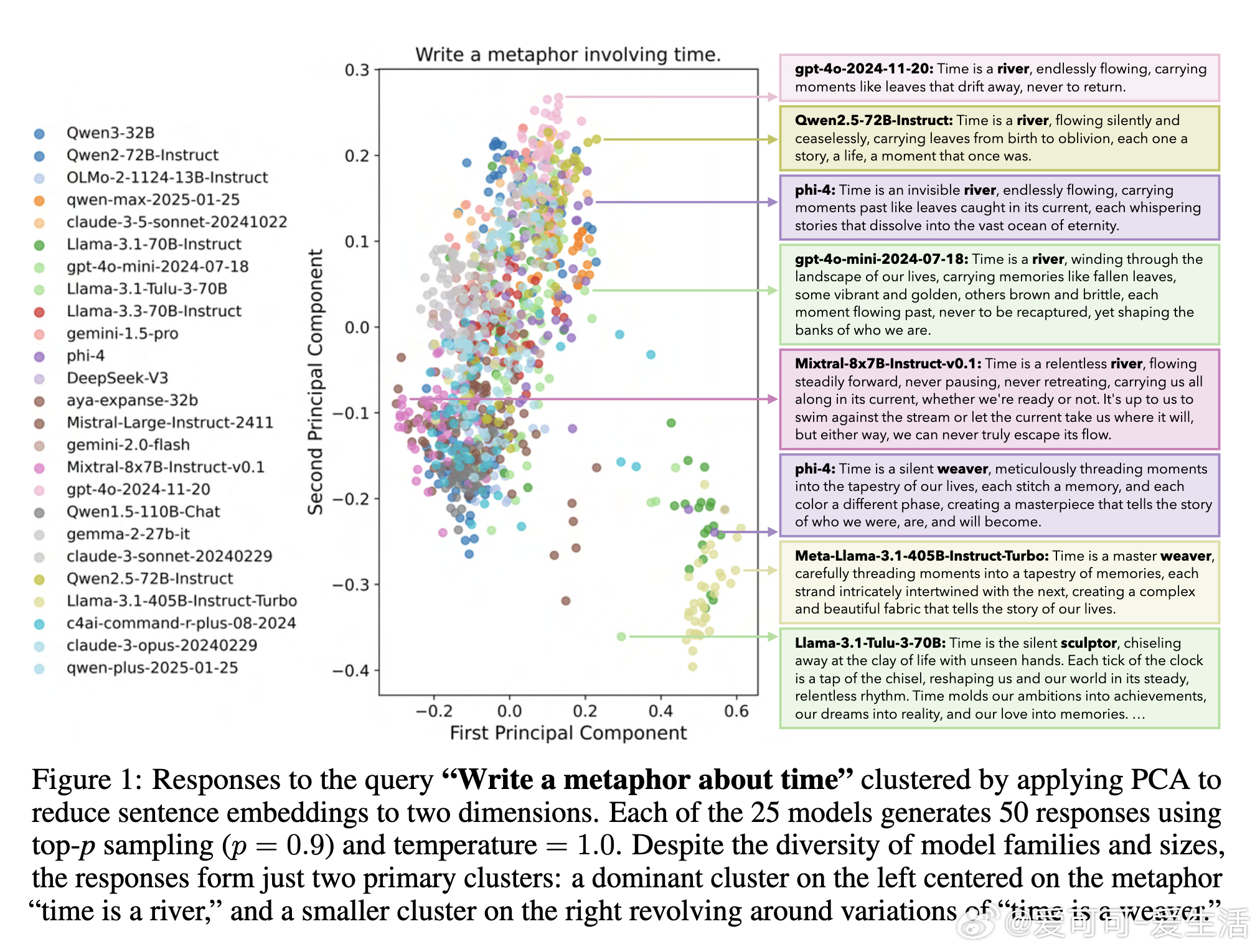
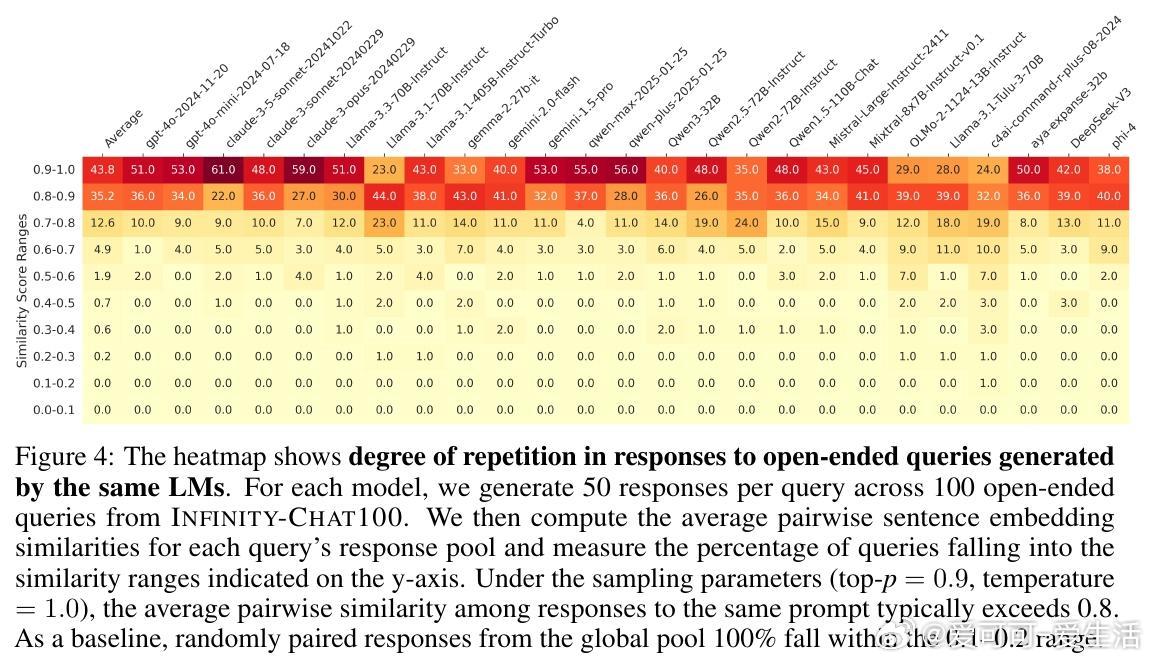
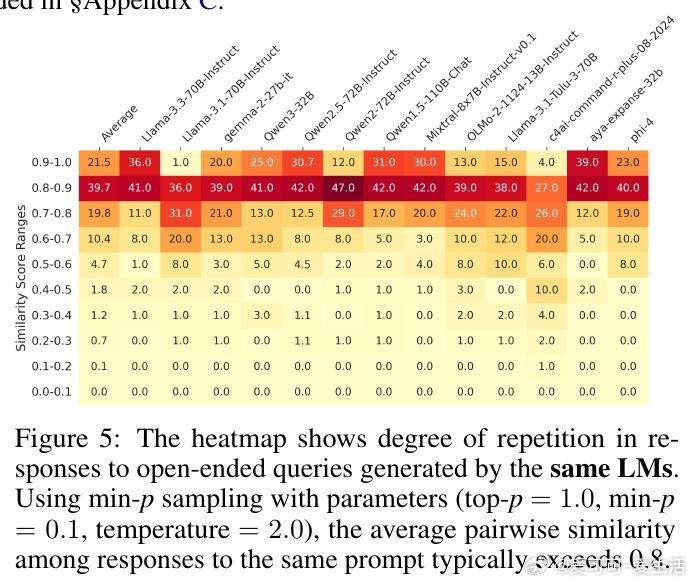
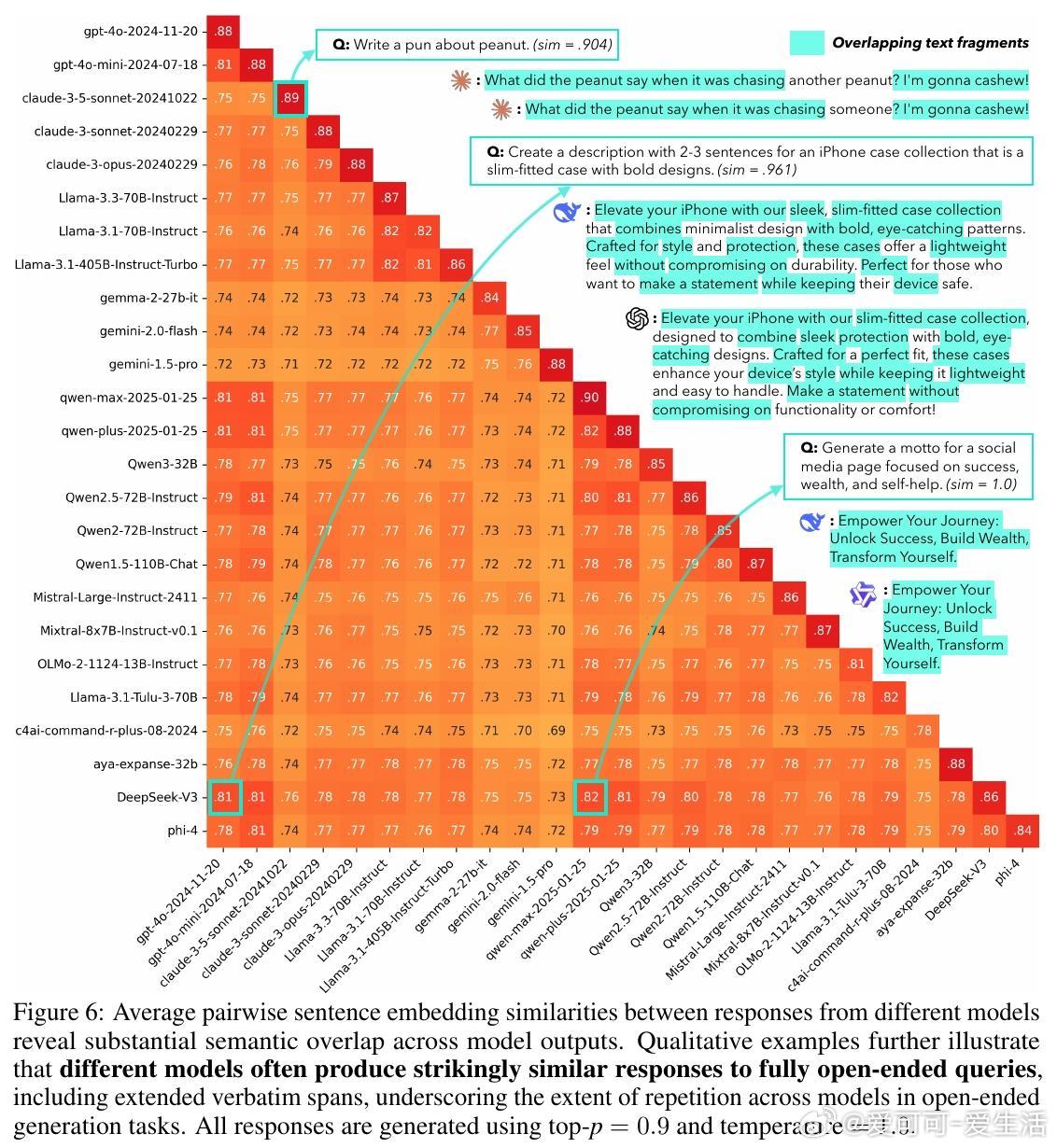
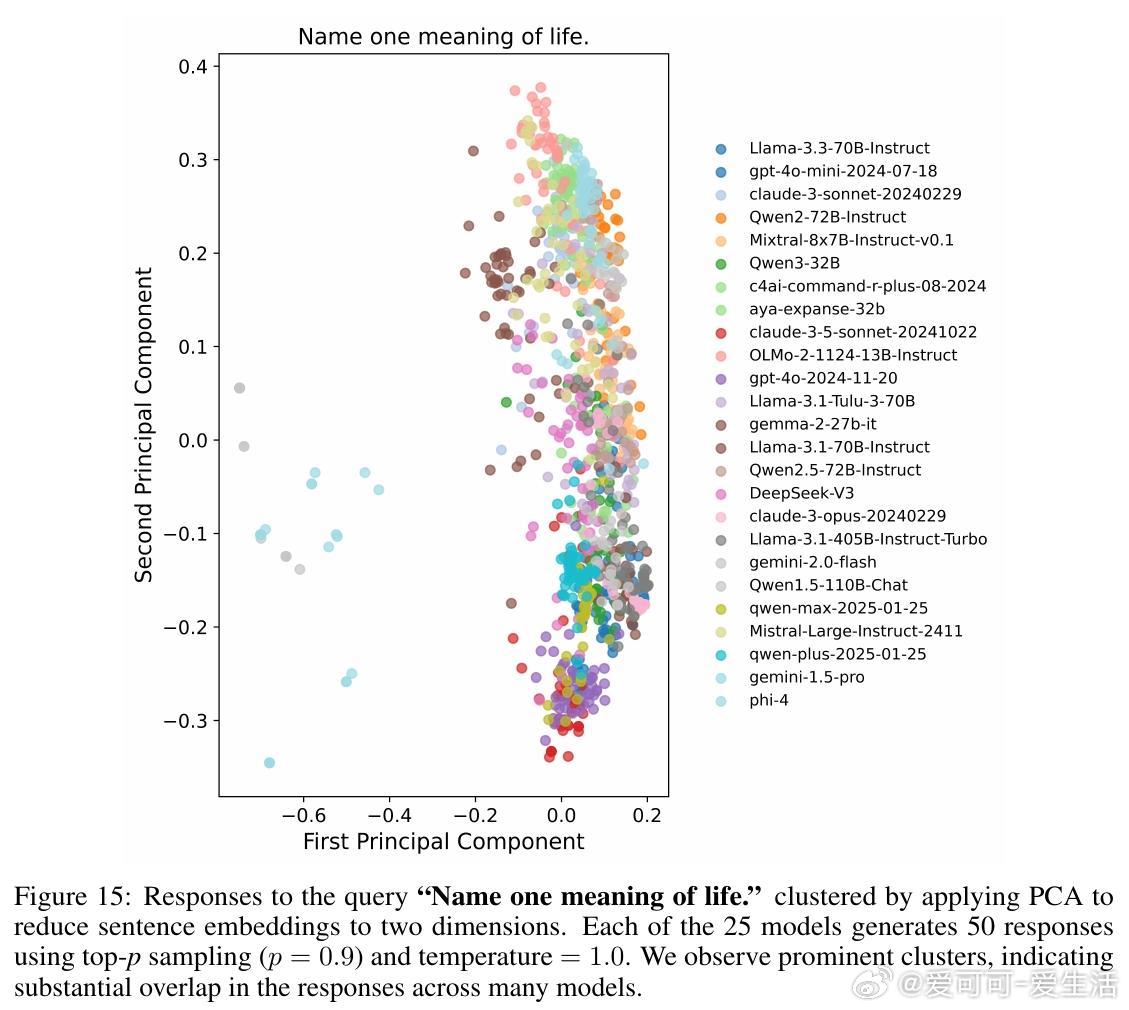
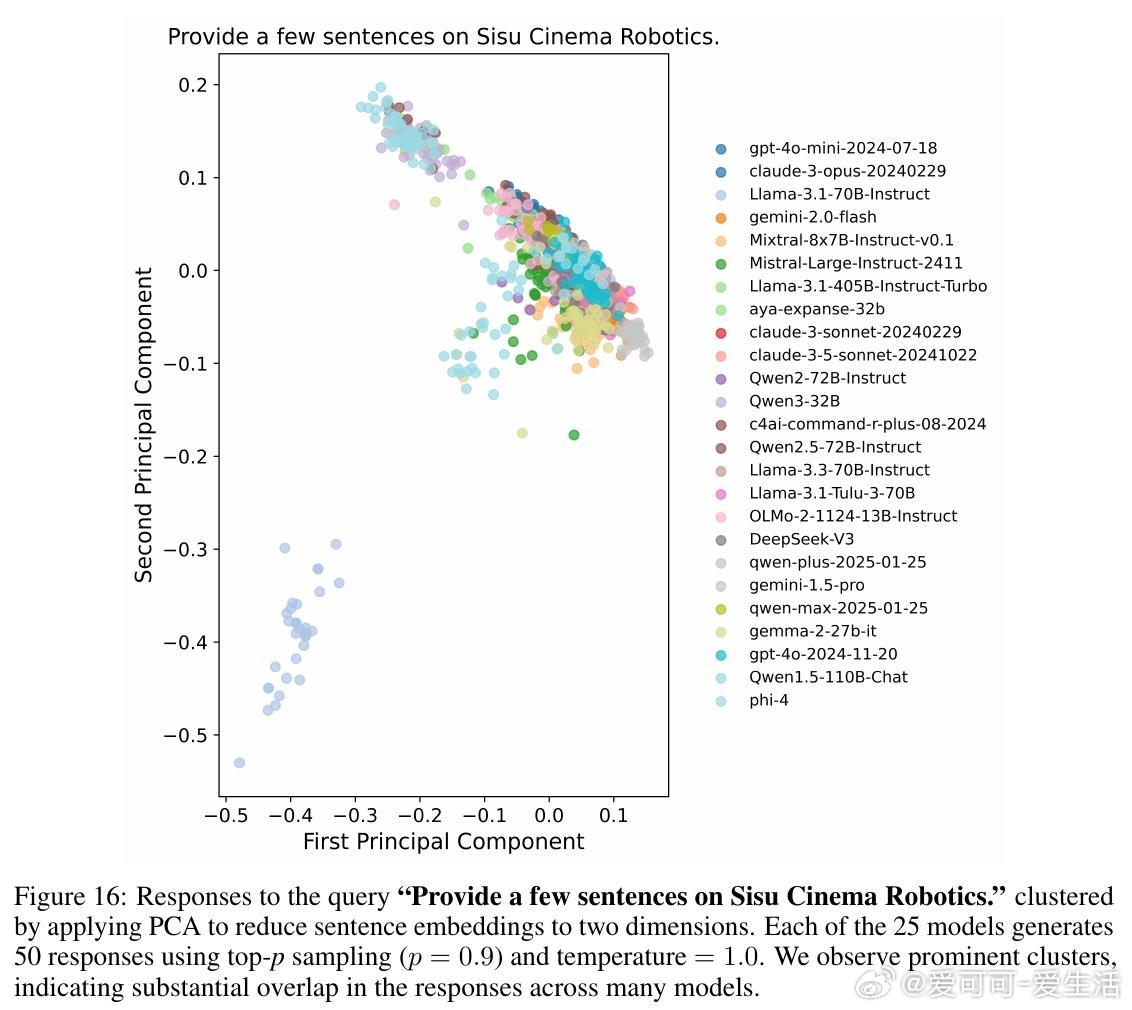
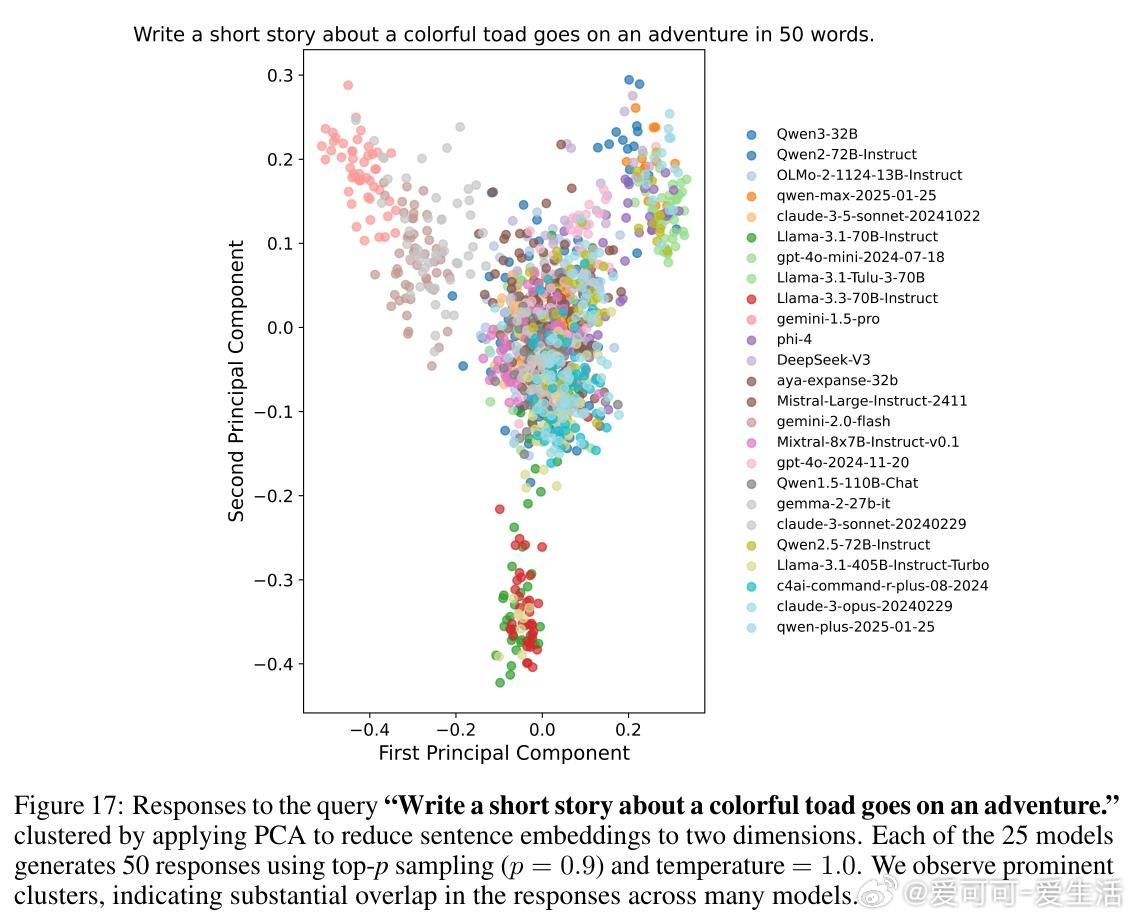
1. 多数模型即使采用高随机性采样,仍然在79%查询中生成高度雷同回答(相似度>0.8)。
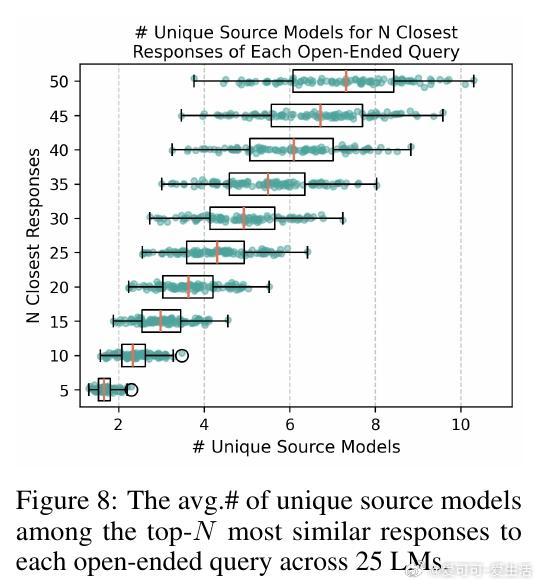
2. 跨模型间回答相似度高达71%-82%,显示多模型集合并不能保证真实多样性。
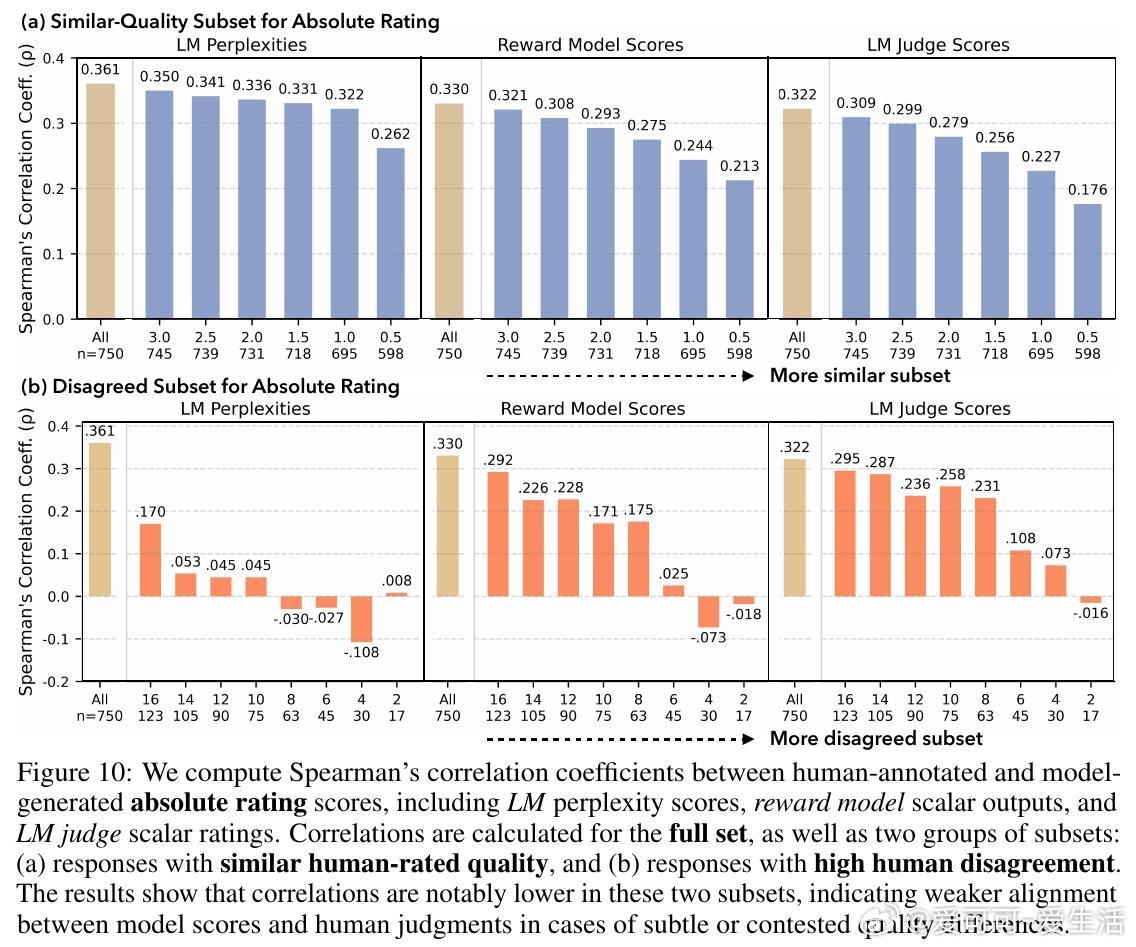
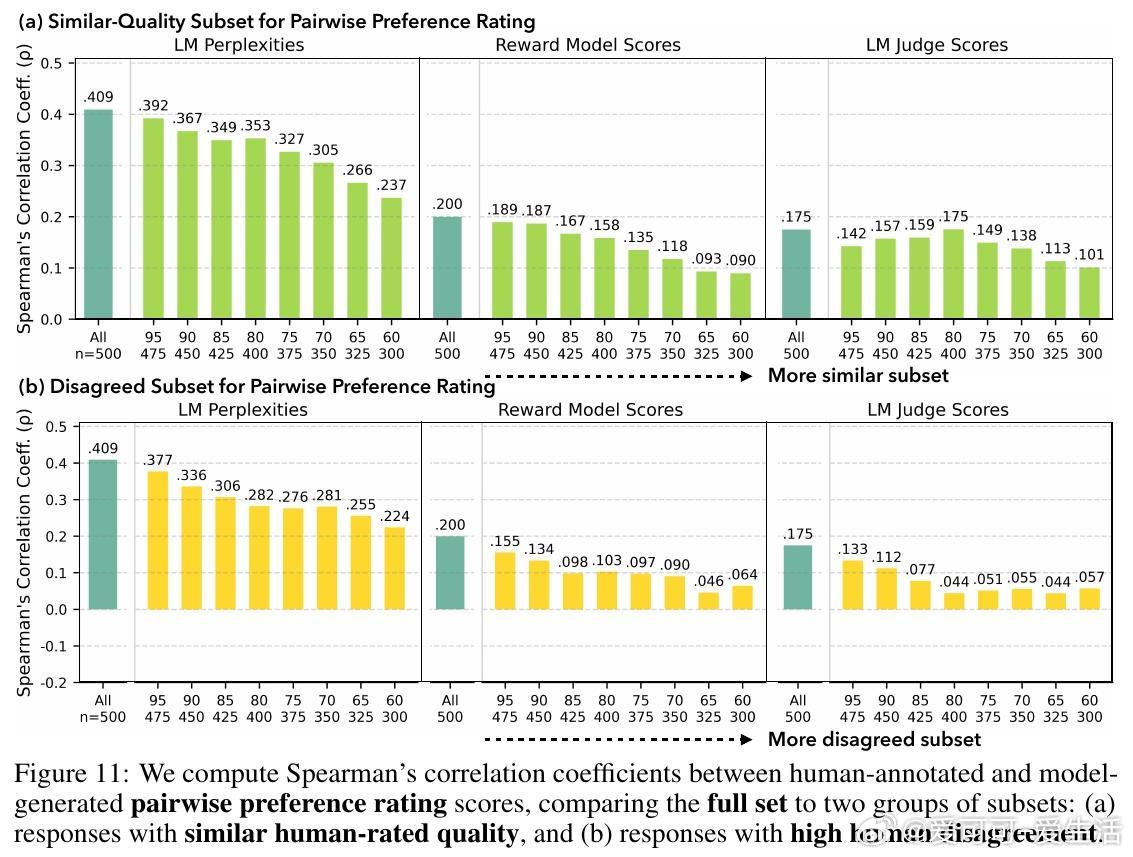
3. 现有奖励模型与LM评判者在面对人类多元偏好时校准不足,无法准确反映多样化“优质”回答。
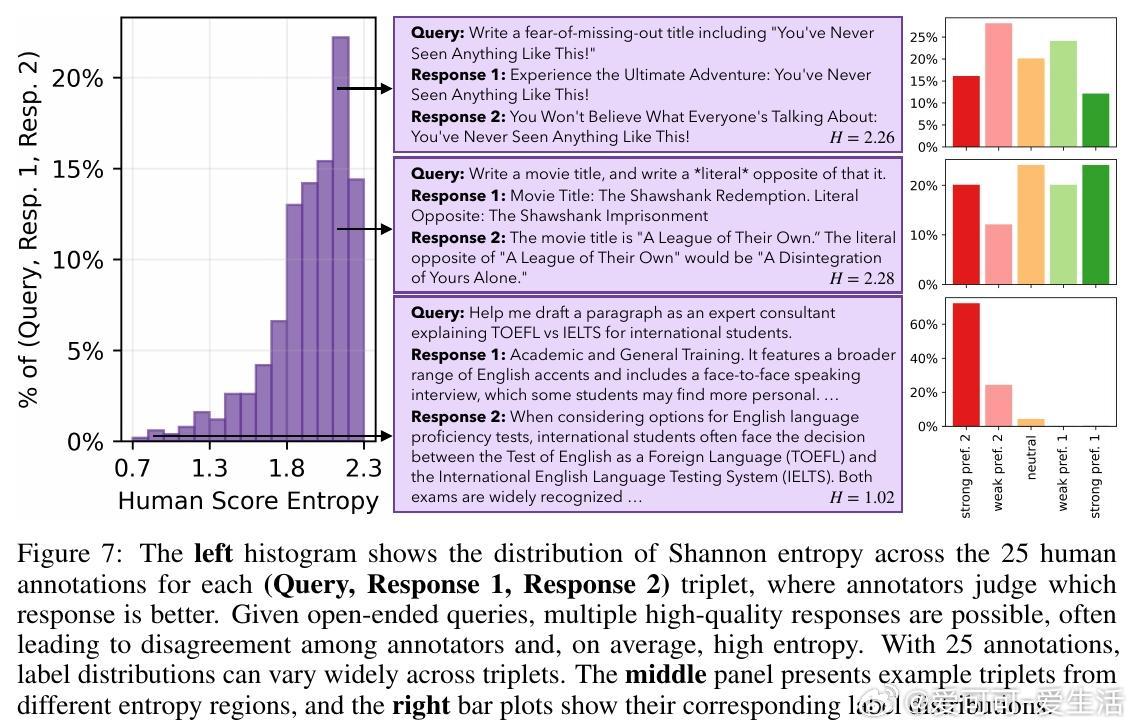
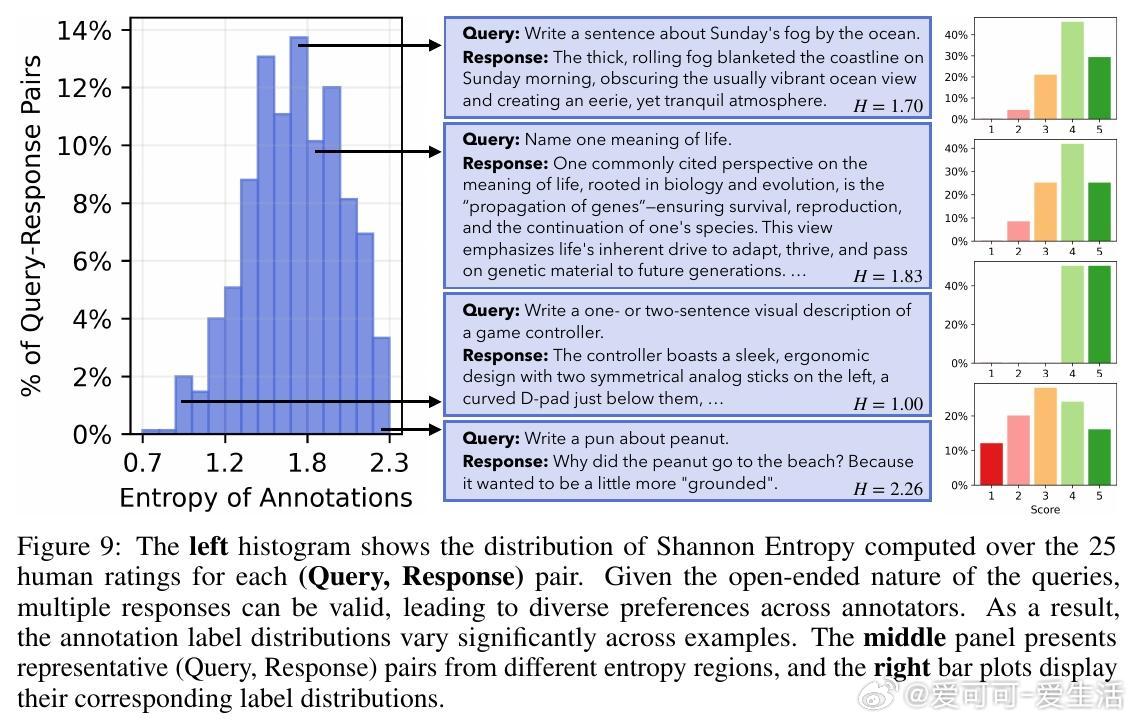
4. 对开放式问题,人类评审存在显著分歧,表明多样化回答均具合理性。
研究呼吁:
- 需从模型训练和设计层面引入多样性导向目标,超越单一质量标准。
- 发展更精准的多元化评估指标和校准机制。
- 关注AI输出趋同对文化多样性和创新潜力的长远影响,促进包容多元的AI价值观。
该研究为语言模型多样性问题提供首个大规模、真实世界数据集和系统分析框架,助力未来安全且富有创造力的AI发展。
完整论文:arxiv.org/abs/2510.22954
数据代码地址: github.com/liweijiang/artificial-hivemind