[CL]《Incentivizing Agentic Reasoning in LLM Judges via Tool-Integrated Reinforcement Learning》R Xu, J Chen, J Ye, Y Wu... [Google Cloud AI Research] (2025)
激励大型语言模型(LLM)评审者的主动推理:工具集成强化学习新框架
1/ 在LLM生态中,模型评审者担负着自动评价生成内容质量的重任,替代人类评审,助力模型训练和推理质量控制。但传统评审多依赖文本内推理,难以准确验证复杂约束和计算。
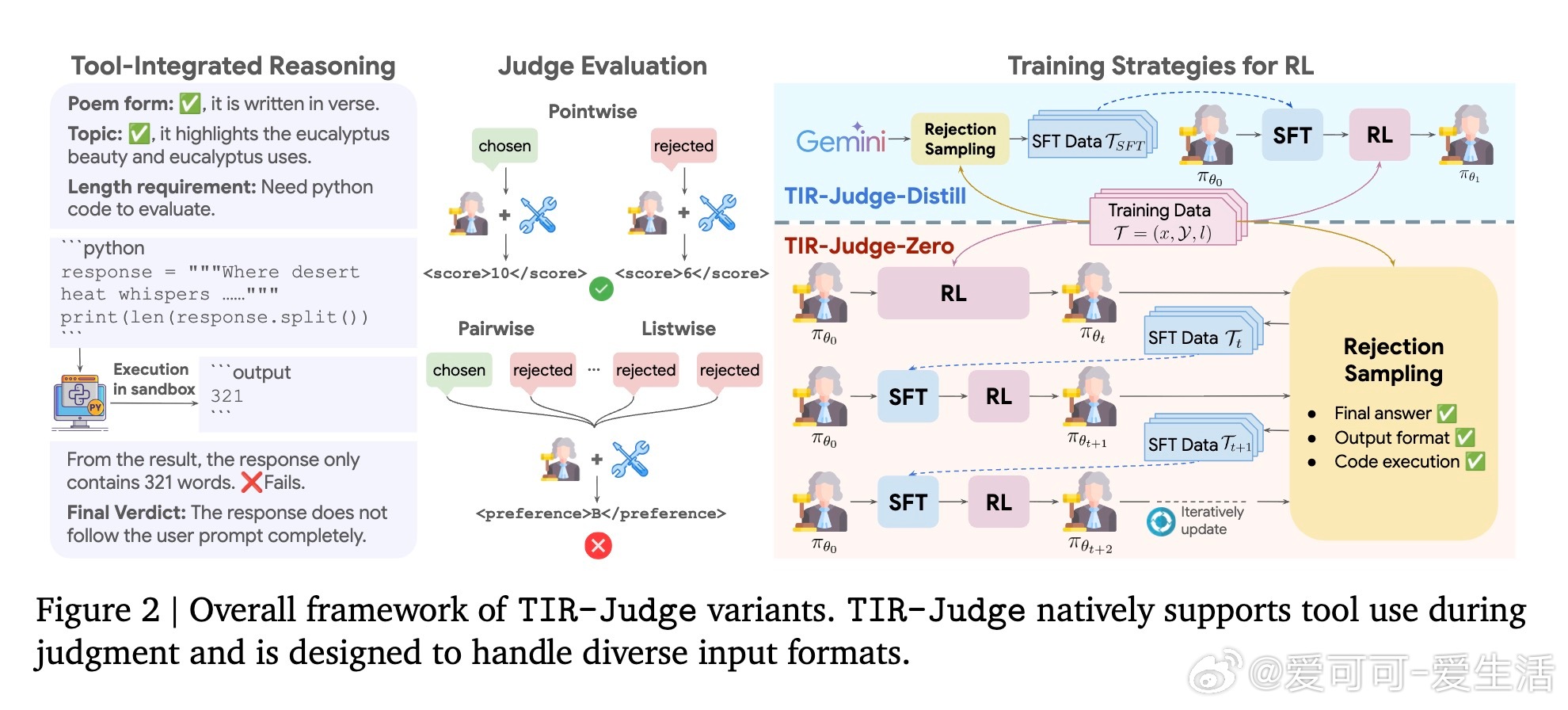
2/ 本文提出了“TIR-Judge”,一种结合代码执行器的端到端强化学习(RL)框架,允许评审者生成代码并执行验证,从而实现精确的判定。核心三原则:任务多样性(可验证与不可验证领域)、灵活判定格式(点对点、对比、列表)、迭代RL训练自我提升。
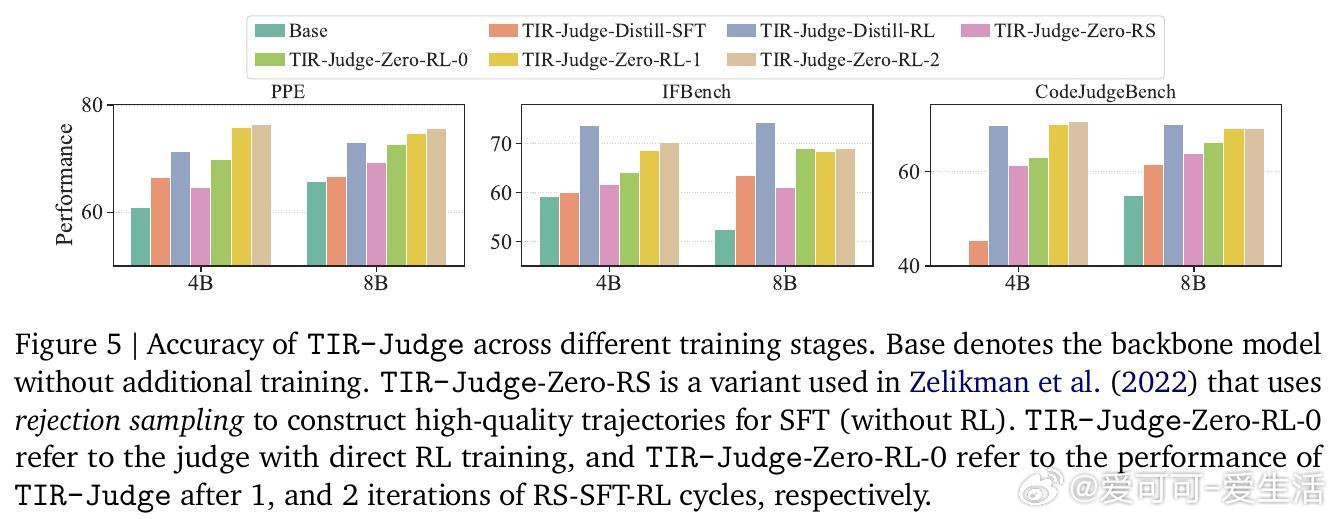
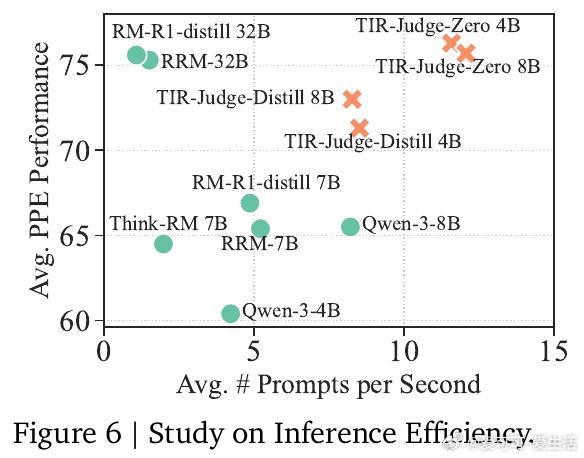
3/ 实验涵盖7个公开评测,TIR-Judge在点对点评测中最高提升6.4%,对比评测提升7.7%,列表评测表现达Claude-Opus-4的96%(参数仅8B)。更惊艳的是,完全无蒸馏训练的TIR-Judge-Zero表现与蒸馏版相当,彰显纯RL可引导工具增强的自我进化。
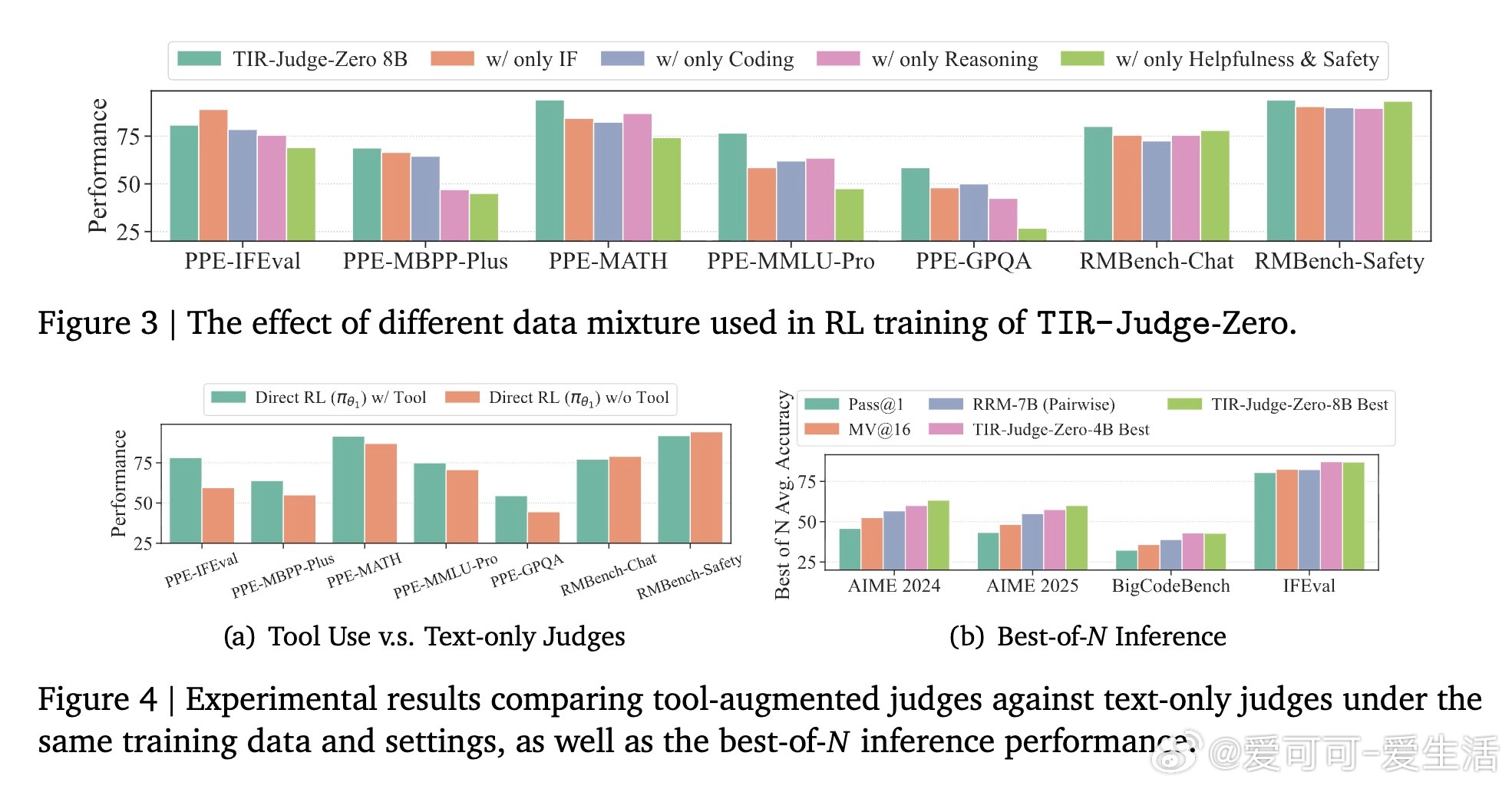
4/ 该方法通过扩展训练数据,覆盖多样任务与格式,自动生成并筛选高质量偏好对,结合代码执行反馈,设计了正确性、格式、工具使用三层奖励体系,确保评审输出准确且规范。
5/ 与纯文本评审相比,工具集成使模型能验证复杂计算(如数学、代码执行),避免文本推理易错盲区。RL训练显著激发模型生成有效验证代码的能力,实现推理与工具深度耦合。
6/ 在应用层面,TIR-Judge不仅提升评审准确率,还能通过最佳N选策略优化下游模型输出,尤其在数学竞赛、高难度代码生成等任务中优势明显,表现优于当前多款大型基线模型。
7/ 作者强调未来将拓展工具类型和训练任务,进一步提升评审能力,期望TIR-Judge成为推动LLM训练和评估生态健康发展的关键技术基石。
论文链接:arxiv.org/abs/2510.23038
总结:TIR-Judge创新性融合工具执行与强化学习,显著提升LLM评审者的判定准确性和鲁棒性,开启了自动评审的高精度、可验证新时代,值得关注与深入研究。