[LG]《Understanding Outer Optimizers in Local SGD: Learning Rates, Momentum, and Acceleration》A Khaled, S Kale, A Douillard, C Jin... [Google Research & Google DeepMind & Princeton University] (2025)
深入解析 Local SGD 中外层优化器的关键影响,突破传统认知,优化大规模分布式训练效率。
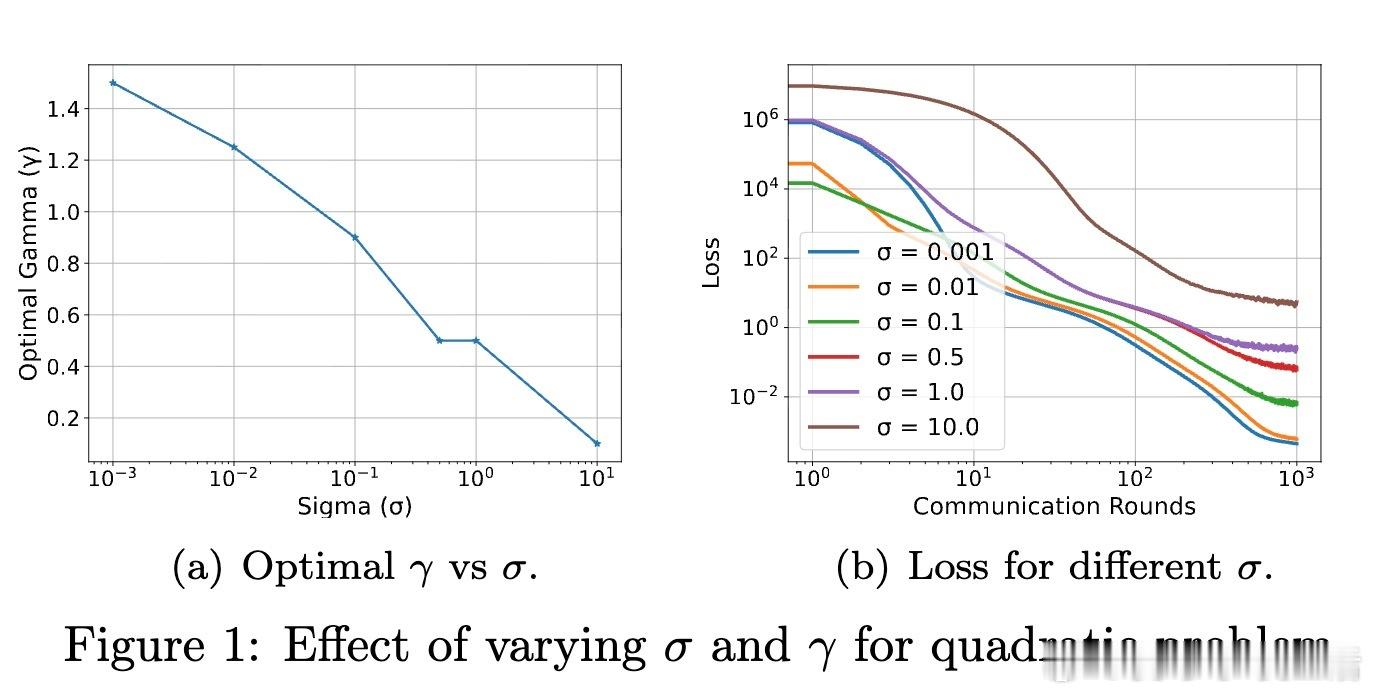
• Local SGD 由本地优化、节点更新聚合及外层优化器三部分构成,外层优化器的学习率 γ 不仅平衡优化误差与梯度噪声,还能弥补内层学习率 η 的调参不足,理论上 γ 可取大于 1 的值,突破以往设定。
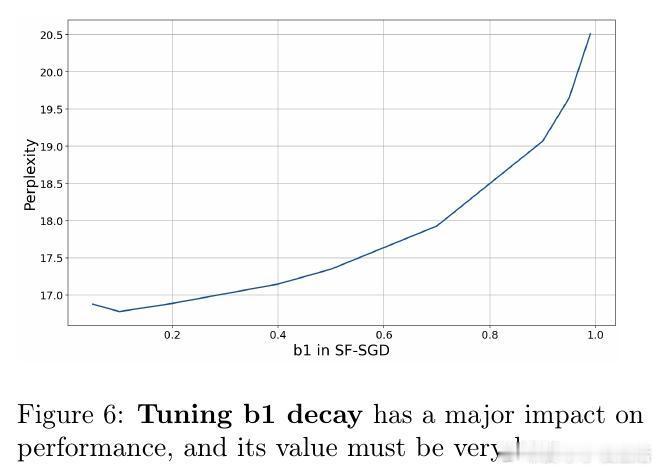
• 引入外层动量 μ,实际等同于调整有效步长 γ/(1−μ),拓展调参空间,提升训练稳定性与收敛速度。
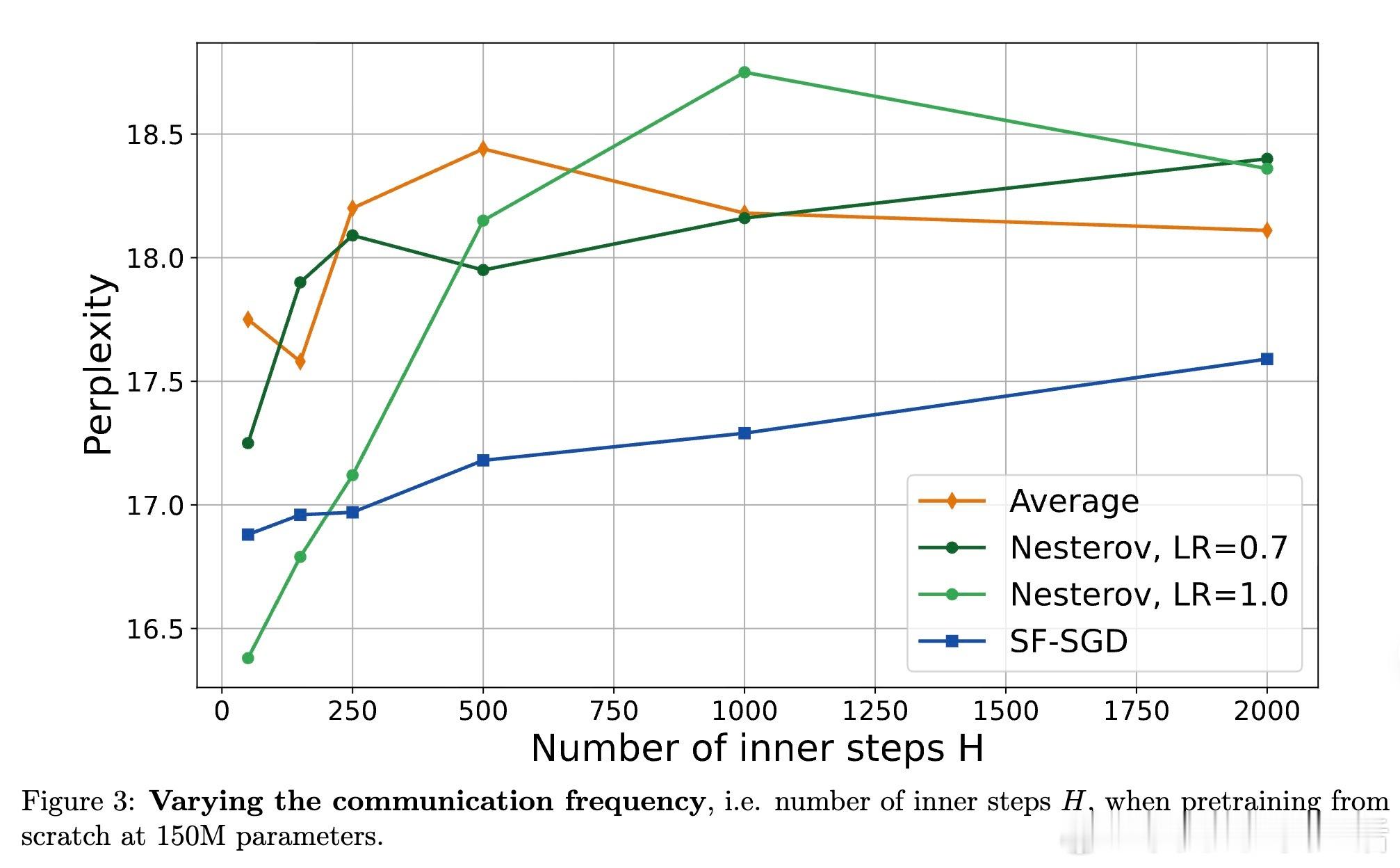
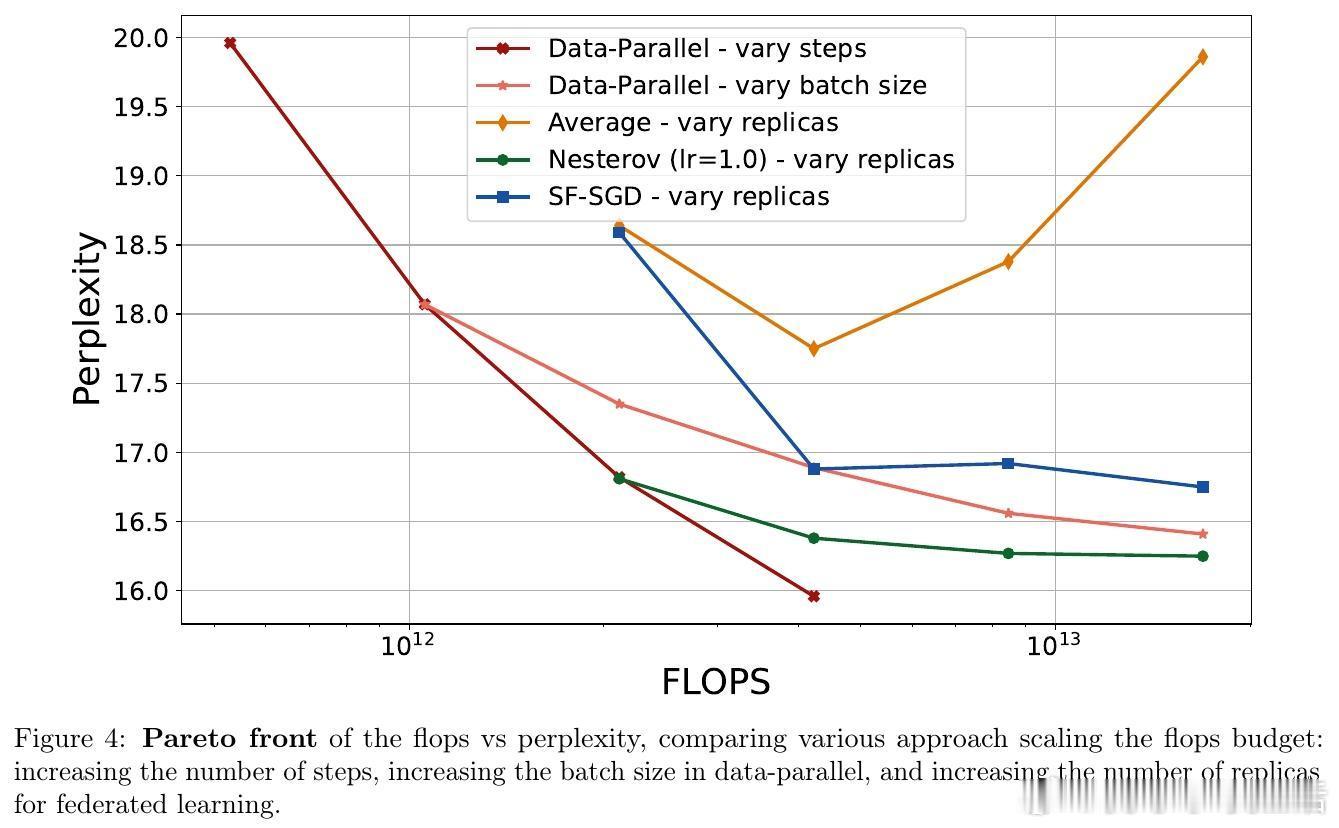
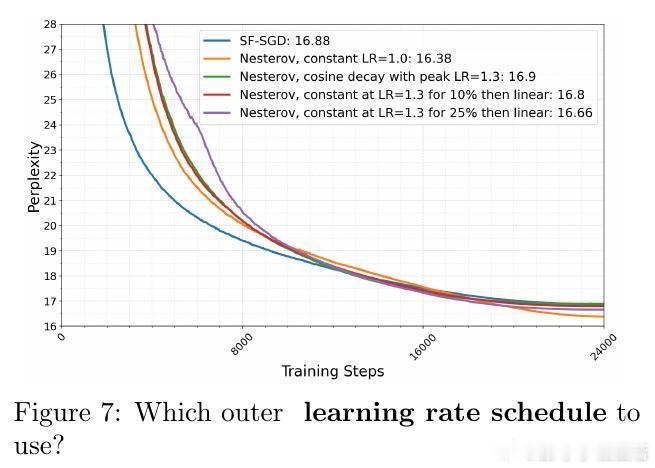
• 采用 Nesterov 加速的外层优化器,在通信轮次 R 上实现加速收敛,优于传统局部加速算法,特别适合通信受限的大规模多设备协同训练。
• 提出首个数据依赖的高概率收敛保障,揭示外层学习率 γ 在不同噪声及梯度分布条件下的动态调优策略。
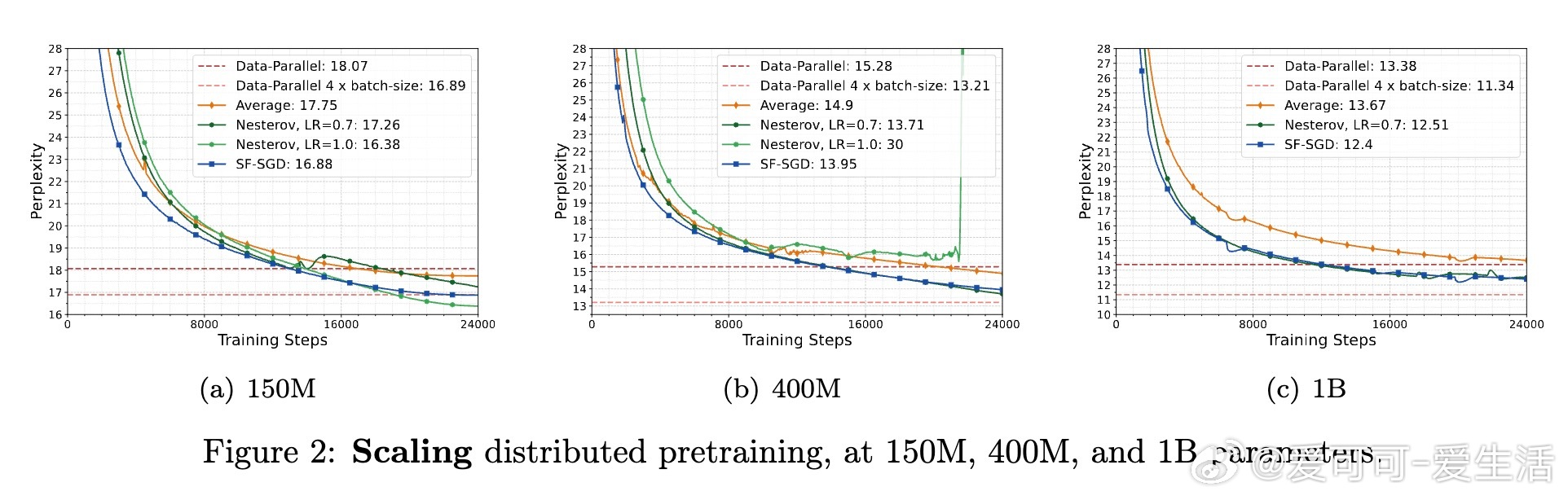
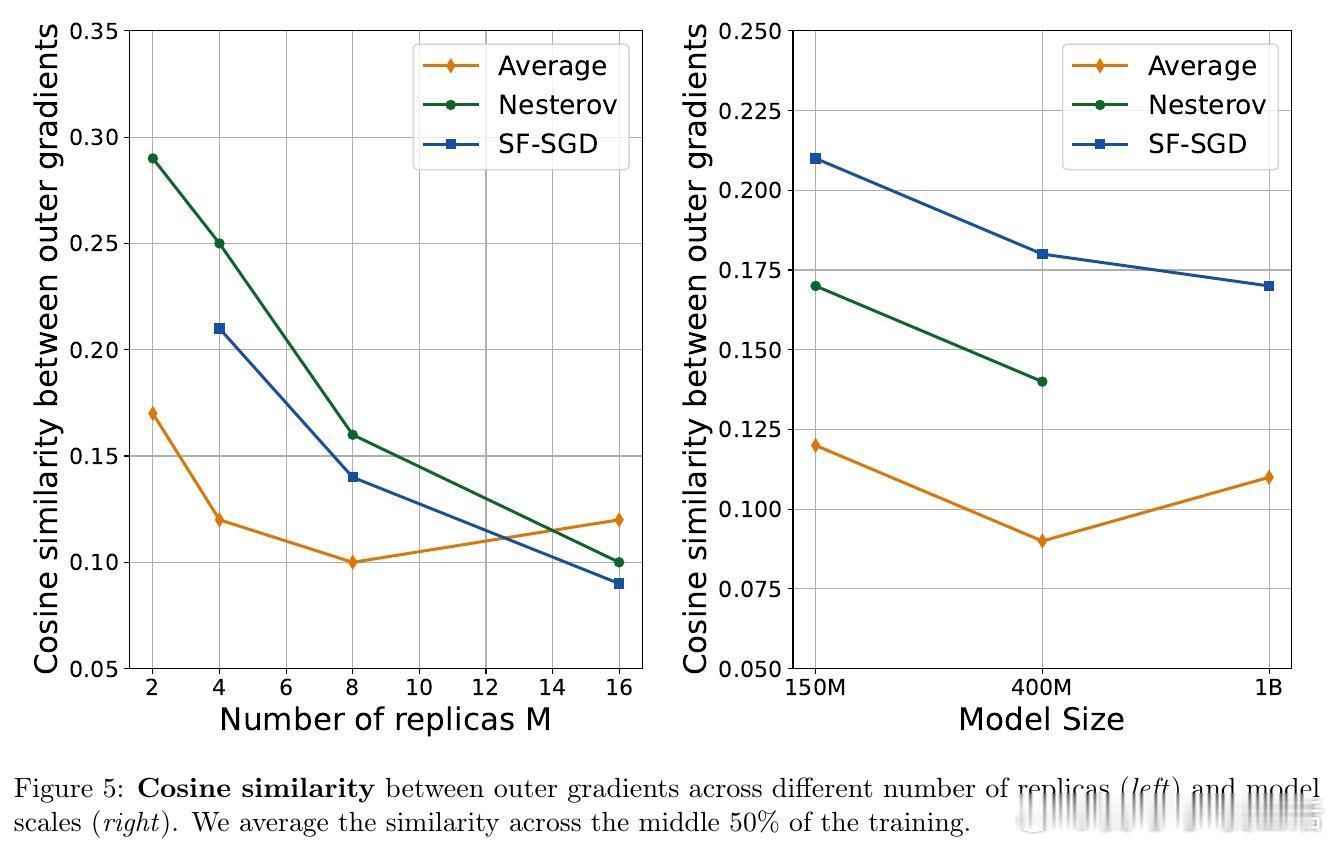
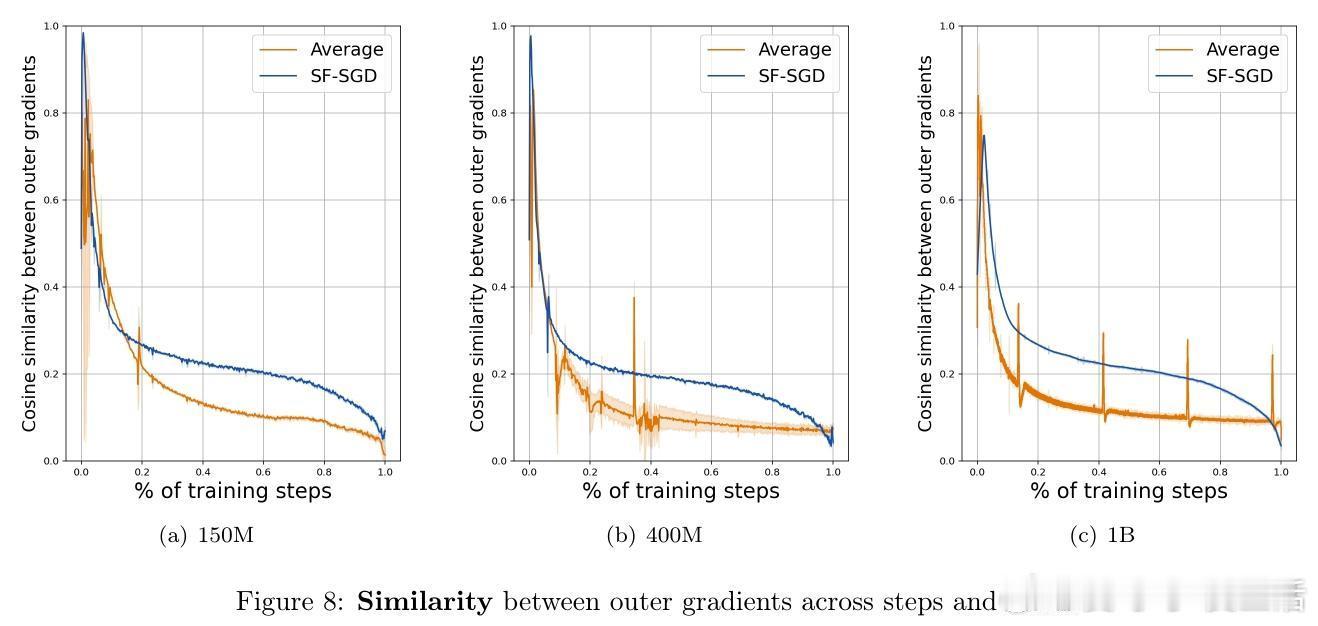
• 语言模型预训练实验证实理论,表明在多种规模(150M 至 1B 参数)和分布式环境中,适当增大外层学习率和使用加速优化器均能显著提升性能与训练效率。
心得:
1. 外层学习率的双重角色打破了局部 SGD 固定 γ=1 的传统,赋予模型更灵活的训练策略,实现了优化速度和噪声容忍度的平衡。
2. 动量与加速技术在外层优化器的引入,揭示了分布式训练中“服务端优化”的潜力,优化了通信开销与计算资源的利用效率。
3. 数据依赖的分析框架为实际大规模系统提供了具指导性的调参依据,提升了算法对不同任务和硬件环境的适应性。
详情🔗arxiv.org/abs/2509.10439
分布式优化联邦学习LocalSGD加速优化机器学习理论大规模训练