奖励模型也能Scaling
强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。
然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。
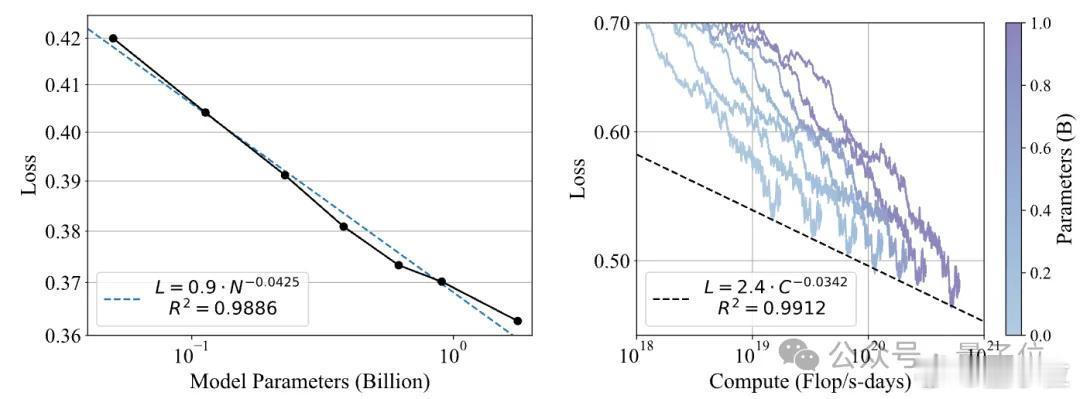
当前,大模型在Next Token Prediction和Test-time Scaling两种扩展范式下,通过大规模的数据和模型扩展,实现了能力的持续跃升。但相比之下,奖励模型缺乏系统性的预训练和扩展方法,导致其能力难以随计算量增长而持续提升,成为阻碍强化学习链路进一步扩展的短板。
如何解决?
现在,来自上海人工智能实验室的研究团队提出了一种新的思路:
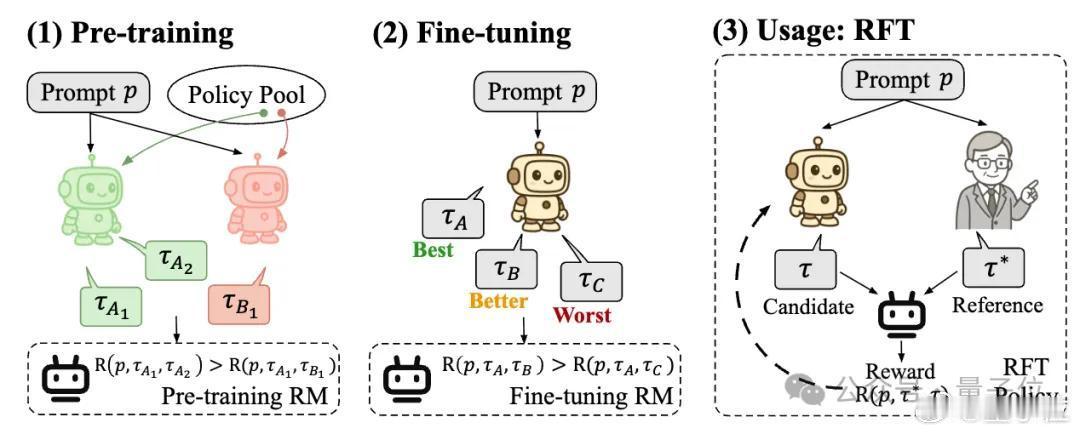
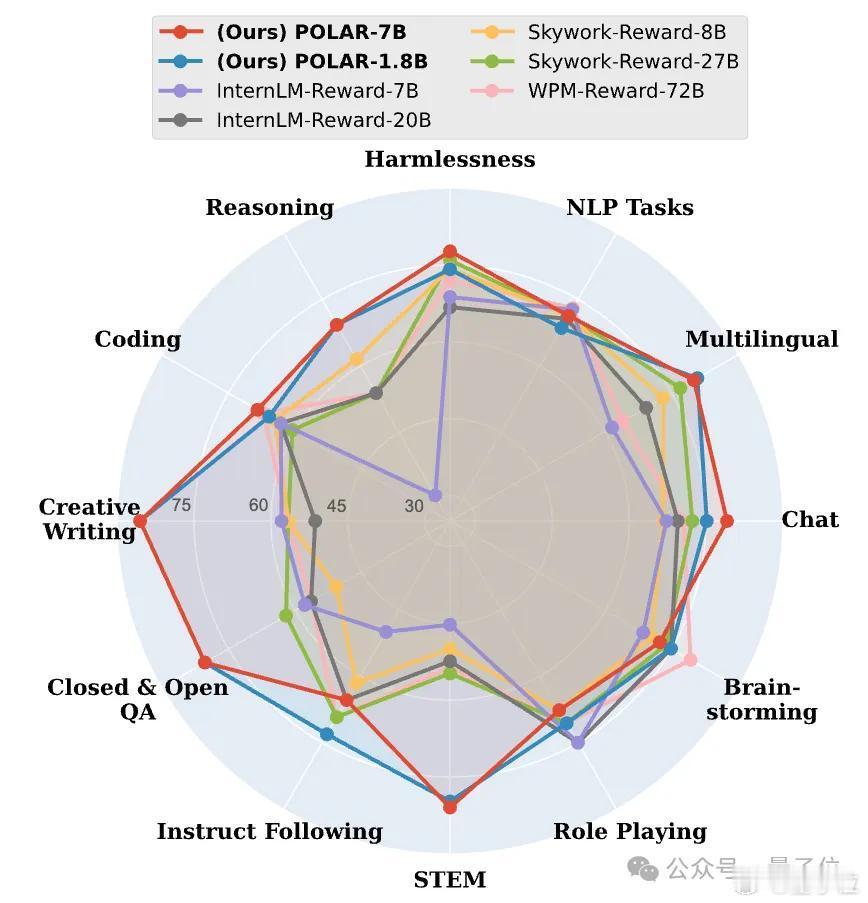
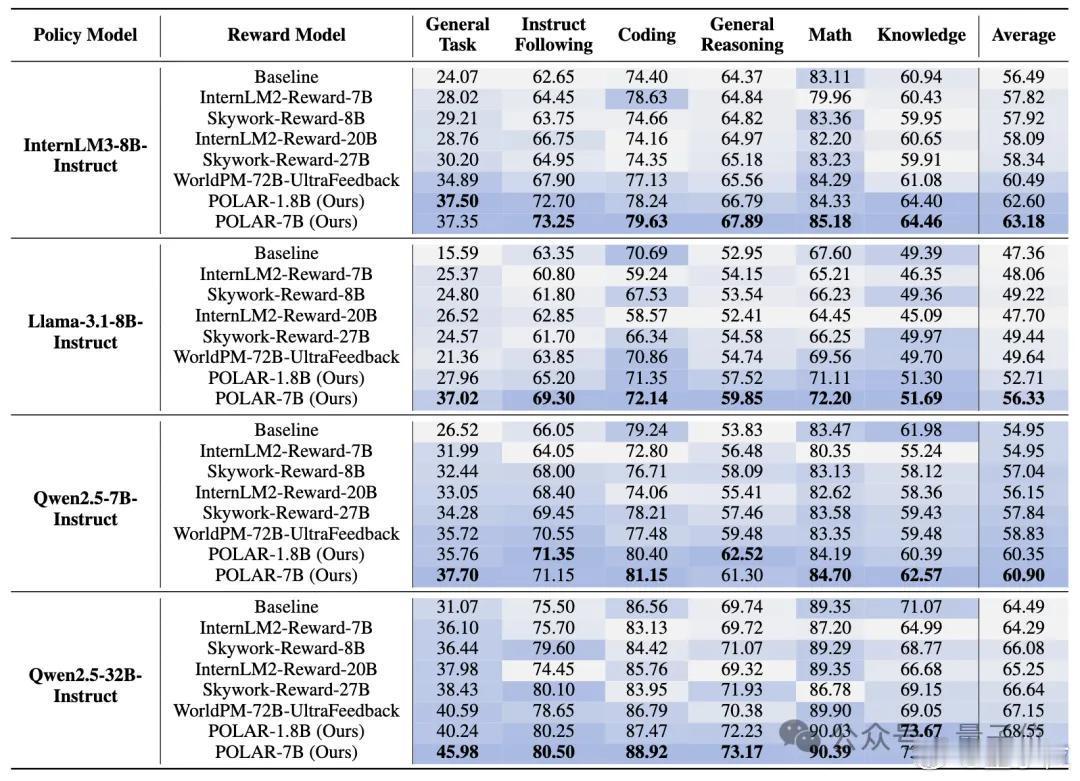
他们找到了一种与绝对偏好解耦的、可以真正高效扩展的奖励建模新范式——策略判别学习(Policy Discriminative Learning, POLAR),使奖励模型能够像大语言模型一样,具备可扩展性和强泛化能力。
POLAR为大模型后训练带来突破性进展,并有望打通RL链路扩展的最后一环。
论文链接:
项目链接:
模型链接: