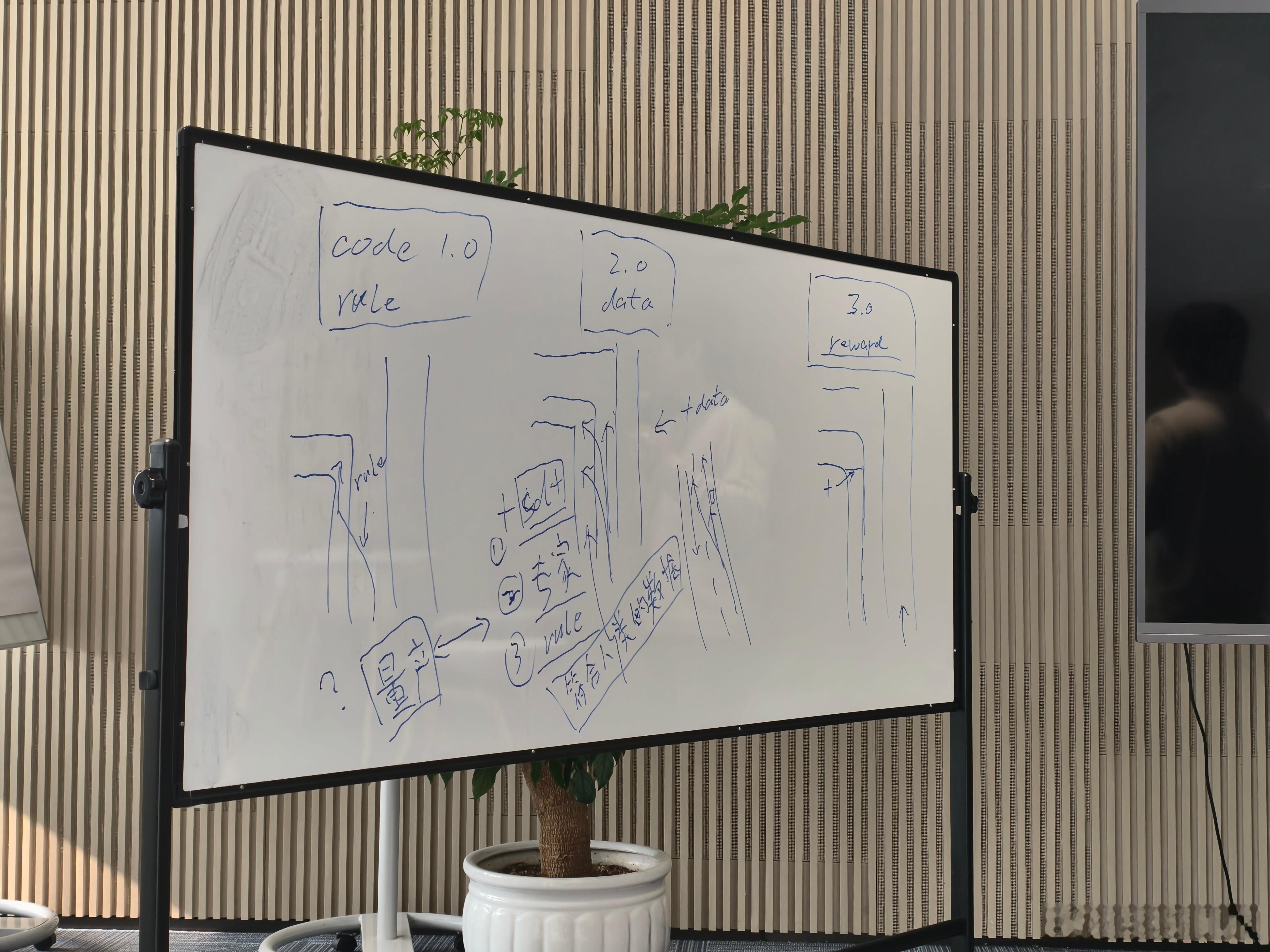
蔚来 NWM 2.0 已经推送了,各家的评测也都出来了,先收到更新的朋友应该也都用上了。这个版本提升毫无疑问是巨大的,是一个从「有」向「好」的转变的版本。之前体验新版本 NWM 的时候,蔚来也把少卿拉出来做了详细的分享,分享结束还有 1 个多小时采访沟通。少卿详细分享了当前技术路线存在什么问题,蔚来为什么切换了新的技术路线,这些是这次能力提升背后的东西。帖子比较长,写个目录吧1. 现阶段基于模仿学习的端到端存在什么问题?行业里是如何解决的?2. 蔚来想用什么方式解决问题?这种解决问题方式的原理是什么?3. 这个技术路线的难点和挑战在哪?4. 少卿认为接下来依然重要的是什么?首先 NWM 2.0 相比 1.0,蔚来内部迭代了新的研发范式,这也是为什么 NWM 2.0 比之前预期来的晚了一些。过去辅助驾驶发展可以分为 2 个阶段:Code 1.0:规则时代,遇到问题就通过加规则来解决,这个阶段的问题也很明确了,规则无法穷尽,而且越复杂的场景规则也越难写。Code 2.0:模仿学习时代,这个阶段就是大家很熟悉的端到端,过去很长时间大家都在讨论端到端相比规则的优势,但是很少有人说端到端无法解决的问题。这里少卿举了一个例子,在路口需要跨越三个车道进入最左侧左转道,有人在这个点换,有人在那个点换,有人很早就完成了换道,到底应该学习哪一种?如果模型看到了所有这些数据,可能会选择一个折中的「平均」,对于左转,这可能还好,但如果是一个左右都有选择的情况,模型选到中间状态,就会出问题,这类情况会导致模型决策混乱。这个情况在我们之前横评里也提到,最左和最右都有左转车道的情况下,系统选道会纠结,也会出现选道很不聪明的情况。想要解决这个问题有 3 种方式:1. 增加 SD+ 地图,地图会给指示在哪个具体位置需要变道,模型只需要执行即可;2. 增加专家数据,之前喂给模型训练的数据不是情况很多样吗?那让专业司机按照规定的开发去开一次,用这个数据去训练模型,出来的结果就好了;3. 增加规则,直接用规则限定车的开法。加地图的弊端在于得花钱;加专家数据的弊端在于要大量人力,针对不同的 corner case,都需要进行专门的采集;加规则的弊端在于限制了模型的能力,回到了最原始的起点。在少卿看来,上面这些做法类似于大语言模型中提到的「对齐人类偏好」,整个系统仍面临数据使用的问题,没有从根源解决问题。好,重点来了,蔚来打算怎么解决?强化学习。这个也是少卿认为的 Code 3.0 阶段,灵感来自于现在发展的如火如荼的语言模型。看语言模型发展的过程会发现,语言模型发展的过程中已经出现过这样的问题。用互联网上几乎所有的语料数据训练大规模语言模型,并通过 token 预测等机制实现对话。因为训练语料来自整个互联网,数据几乎不可能彻底「洗干净」,其中必然包含质量、描述不准确甚至上下文逻辑混乱的数据。这也是 ChatGPT 的最初版本,早期的 DeepSeek,会产生莫名其妙、上下文不连贯回答的原因。所以语言模型在经历了模仿学习阶段之后,进入了 Code 3.0 强化学习时代。关注智驾行业发展的朋友在过去一段时间,应该都听过强化学习这个词了。不过少卿也毫不避讳的说了,在国内实现完整强化学习的系统,目前只有我们这一个。关于这个问题,我也后面也追问了一下蔚来的工程师,他们的意思是,有很多家说上了强化学习,其实只是在某一些小场景里用了,但是蔚来是一个完整的强化学习系统。蔚来上一个版本还是新旧方法混合的状态,NWM 2.0 开始完全转向了强化学习的新范式。所以新的问题是,强化学习的原理是什么。少卿的总结是:可以概括为构建一个仿真环境,并设定一套奖励机制。例如,构建一个仿真环境,告诉模型「你成功通过这个点,就获得分数」,如果能高效通过,用时越短,奖励分数越高,如此循环训练。当然,过程中会有一些更细节的专家数据约束,比如「如果压实线,我再给你扣两分」等。具体在哪个点位变道,如何安全通过三条车道,这些都由模型自己在仿真中探索解决,整个训练状态是如此。这套方法的好处是没有增量数据,也没有复杂的规则,与此同时,让模型可以承受更多的脏数据。为了便于理解少卿还举了一个例子,在模仿学习阶段,一个路口的脏数据如拐弯变道的场景,所有的结果在模型里面是数据分布。如 Top1 分布是 200 m 变线,Top2 是 100 m 变线,其次为 300 m 变线,最后是不变线。优先级的排序纯看数据的分布是什么。所以大家在做模仿学习的时候,很多工程师是选择调数据分布,通过调数据分布的方式来选择优先级,例如希望 300 m 变线,那就把 300 m 调成 Top1。蔚来现在是通过写 reward 来调整优先级,通过强化学习的方式来改变模型偏好分布,改变了模型的行为倾向,把原本排在后面的选项提到了前面,降低了出现奇怪逻辑的概率。其次强化学习可以进行「分阶段重组」。比如把一个任务虚拟化成 10 个或 100 个阶段,强化学习可以把这 100 个阶段重组,并在每个阶段找到最优解,最终组合出一个在原始数据中可能从未出现过的结果。强化学习的另一个好处是,能学到一些之前靠模仿学习学不到的东西。比如在路口窄路会车的时候,你需要有意识的先靠边停车,把对向的车让过去再走,这类场景的难点在于需要具备前瞻判断的「长程逻辑」。这个靠模仿学习很难学到,但是强化学习可以,模型在训练时会对这个场景产生各种各样的尝试轨迹。最终它会发现,只有选择「靠边让行」这条轨迹才能获得奖励,其他选择都不行。通过这种方式,它就能学会正确的处理方式。至于如何做好强化学习,这个其实分为组织和技术两个维度。组织维度是研发团队是否有完成范式转变的决心和执行能力,同时研发团队思维模式也需要同步转变,出现问题之后除了从数据找原因,还得看奖励函数设置的好不好。这个过程和从规则往端到端切的时候是一样的,这里少卿也说这个过程很痛苦,当时内部也是做了 2 个版本,8 月基于新架构的版本出来之后做了一些内部试驾,试了后发现效果挺好,然后开始往量产去推。技术层面回顾一下前面少卿概括的做法:构建一个仿真环境,并设定一套奖励机制。这里详细的技术我无法展开太多,有一个比较有意思的细节是,蔚来现在有一个人机共驾模式,这个模式从产品的维度是提升辅助驾驶体验。但是从研发的维度,通过人机共驾可以产生更多的 Pair(人类标注的成对比较数据)。强化学习除了 PPO 等方式之外,还有 Pair 的数据,相当于「这个好,那个不好,让算法倾向于做好的行为,不倾向于差的」。一条是原先模型规划的轨迹,一条是用户接管,而且用户接管时间/打断的时间比原来是短很多的,三个动作变一个动作了,所以可以拿到很短的时间里面模型是怎么规划的,用户是怎么动的,结合去产生渲染的轨迹。我问了一个我比较好奇的问题,大概意思是奖励机制的设置是否会遇到无数复杂情况,如何将这套方法推广到更广泛的场景?少卿的回答也很坦诚:「技术范式的迭代往往类似 S 型曲线,早期进步快,后期会进入缓慢阶段。到了晚期,也是会有轨迹冲突的情况,这些 reward 什么是好的什么是不好的也是会冲突。大家为什么要迭代范式?因为当一个范式接近其 S 形曲线的后半段时,付出的代价与获得的提升就不成比例了。每一代范式迭代,都是把原来比较「重」的部分替换掉,换上一套新东西,让能力曲线再往上爬一层。」这里说了很多强化学习,但是少卿也反复强调,基础数据量,而且是量产数据仍然是非常关键的。在预训练阶段仍然需要大量数据,而且从某种角度来讲是越多越好,之后再进行强化学习,这个也是蔚来下一步 NWM 2.5、3.0 的核心。虽然现阶段来看,使用专家数据的效果可能会更好一些。但少卿认为,未来一定会进入利用大规模量产数据的状态。现在整个辅助驾驶行业都面临怎么把所有数据用起来的问题,还没有找到能够大规模有效利用比专家数据大 10 倍甚至 100 倍的量产数据的方法。不过少卿判断,这个方向在未来一年,最多两年内会有突破。之所以会有专家数据,就是因为量产数据太脏,现有的能力筛不出来,筛不动了,所以需要去重新采集。强化学习也是为了解决脏数据的问题,当然除了强化学习,少卿也坦言还需要其他技术来解决数据规模和脏数据的难题,这一块蔚来也在持续研究。包括加大数据规模、使用 SD+ 等,都会带来肉眼可见的提升,后续蔚来会在某些版本中逐步加入这些优化。另外,世界模型虽然能通仿真等手段去重建场景,但是本质上都是 Data Annotation。少卿举了一个很形象的例子是,真实世界是一张大饼,采集到的数据是饼上的芝麻,而仿真则是对一颗芝麻画一个圈。但如果在这个区域里原本就没有芝麻,通过仿真是无法凭空变出芝麻的。最后关于辅助驾驶技术是否会和具身智能机器人共通,少卿的回答是:「真实世界的技术确实互相借鉴。但完全的闭环的强化学习,对具身智能而言也是一个新的探索方向。目前,具身智能领域的强化学习大致分两层,一层是像跳舞、翻跟头这类,几乎不需要关心周围环境,只需要知道「地面」存在即可,这属于纯强化学习在虚拟环境中的训练。另一层是当机器人需要与外界交互时,如抓取物体,如何有效利用强化学习仍处于探索期,有一些进展但尚未完全成熟。这方面与智驾有相似之处,但智驾反而有其特点。机器人目前更关注任务的成功率,比如抓取一个杯子,成功率从 30% 提升到 90%,强化学习主要为此服务。而智驾是面向用户的,除了抵达目标,还需综合权衡安心感、效率、距离,如方向盘幅度、刹车加速不要太激进等,比当前机器人领域复杂。」蔚来蔚来智驾蔚来世界模型全新版本发布